Analysis: Shader Core Throughput
To test ALU throughput we've put together some fairly simple DX10 shaders, that are engineered to test a number of cases, whilst removing all other bottlenecks outside of math prowess. We had to ensure that the loops we used were long enough to extract maximum rates from Cypress:
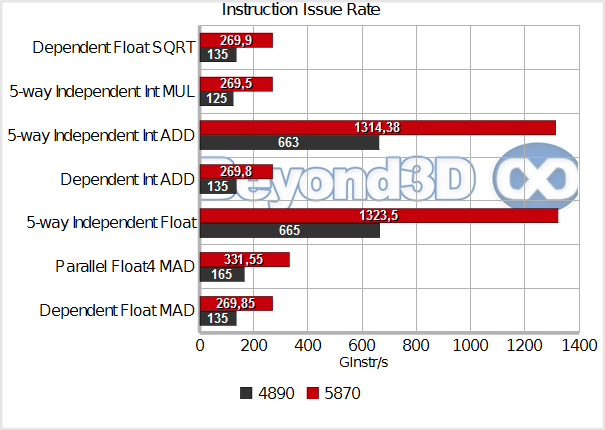
Each test is pretty suggestively named and should tell you what each is doing. It's interesting that even in these simple shaders we're not managing 100% issue rate (that would be 1360 GInstr/s for Cypress and 680 for RV790), which is probably tied to what we've already discussed about the peculiarities of accessing GPRs. In the dependent float MAD test you can see that the newly implemented MUL+dependent ADD “co-issuing” doesn't bring increased instruction issuing, but, as you'll see when tested in a high register pressure scenario, there are other benefits.
Instead of SQRT you can place any transcendental (and we have) and throughput will remain the same. Our integer MUL test was ill setup for illustrating the new 24-bit MUL support included in the slim ALUs, and since we no longer have a sample on hand checking that out will have to wait a bit.
What's pretty obvious is that there's no huge change here in terms of what the shader core likes or dislikes, versus prior parts, however, the sheer count of ALUs means that even in purely serial code, written in anger, the hardware will produce some respectable numbers (coincidentally, R600 issued 236,8 GInstr/s in a best case scenario, impressing folks back then, whereas Cypress does 269 in its worst case one now).