Analysis: Goodies
What we have here before we conclude is a collection of novel measurements (for the hardware analysis community anyway), made relevant by the rise of the GPU compute trend. We'll begin by looking at shared memory throughput. We sought to use an access pattern that's as optimal as possible (on paper, there should be no conflicts), kept the per thread group shared memory requirements low – 2 KB arranged as UINT2, which means up to 16 thread groups can be resident on an SM/SIMD – and did no math/extra work beyond the absolute minimum (for reads we had to preload data, but we tried to amortise this cost by looping reads multiple times). Here are the results:
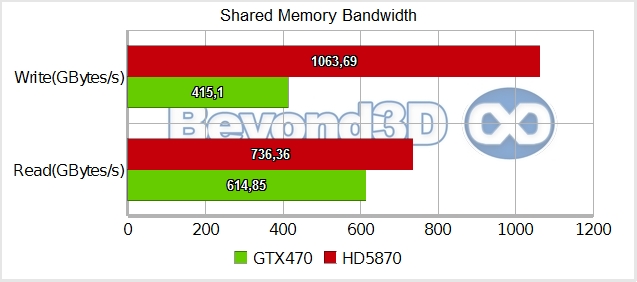
In spite of our best efforts, results aren't that impressive on either side of the fence, with both GPUs falling quite a bit off the theoretical maximums – granted, it's possible that with further tweaking we can achieve even better throughput, but one can safely say that the impressive shared memory bandwidth figures that we see quoted in marketing presentations aren't exactly trivial to achieve. As an interesting tidbit, we noted that Slimer was more sensitive to access conflicts, with performance degradation when we purposefully generated access contention being a bit sharper.
Another useful tool is represented by atomics, with a fast implementation of them making a number of algorithms possible. Atomics can use operands both from shared memory as well as from VRAM – let's look at the first case (prepare for a bit of shock):

Hoping that everyone who fainted was exposed to smelling salts, let's underline that the above is correct: in our considerable experience, Cypress is ~12 times faster here. Try as we might, we couldn't get Slimer to perform better – and these are un-contended atomics ops and we're using MAX without returning the original value, which should pretty much qualify as a best case scenario. What's up with this? You'll read our theory a few paragraphs below, once we get to discuss atomics in global memory.
Moving in a logical progression, we should also see how VRAM-based atomic throughput looks. For this we use a 256 MB wad of memory, to hopefully mess up caching a bit and have main VRAM as the limiting factor. We interpreted it either as a Structured Buffer or a Byte Address Buffer, accessing either a single 32-bit value or a vec4 of 32-bit values, once again using an access pattern designed to be optimal and let the driver and hardware coalesce accesses nicely:

Here you can catch a glimpse of the painful truth that most people ignore when drooling over GPU paper flops: extracting optimal performance requires architecture-specific work to a greater extent than on a CPU. What we're doing is quite trivial, and yet it easily exposes large performance cliffs: Cypress likes to write vec4s whereas Slimer really hates it, with the tables being reversed if one writes a scalar 32-bit value. This is one of the easier-to-spot gotchas, of course, but there are many more waiting in the shadows, seeking to nom the daring developer that wants to take up GPU compute. Reads are better, with good throughput being seen everywhere with the mention that using a Byte Address Buffer makes Cypress lose a bit of performance (the workload is the same, mind you).
The final slice of so called goodies has us look at atomics in global memory. We use a 32 MB Structured Buffer of UINT2s for this – atomics are per component on the UINT2, mind you), using the {Increment,Decrement}Counter -- using the buffer from above but adding the hidden counter, and not reading back the counter value -- functionality and, last but not least, Append/Consume Buffers (each gets a 32 MB Structured Buffer of UINTs, and we Append/Consume one UINT per thread):

Excluding atomics, where it's roughly 3 times faster, Slimer loses everywhere here too. That's a bit surprising for a GPU that supposedly forfeited graphics for compute, and is probably just a retrofitted compute only device. So what's the story? Starting with atomics, you'll note just how close the numbers are to the ones we got when using shared memory operands (no guys, we didn't accidentally the whole operand storage).
It is our opinion that on Fermi there's no difference between the two, with the former possibly being a bit worse actually, and here's why: we think that it can only perform atomics using the ROPs on operands that are in the L2; as such, when doing atomic ops on shared memory operands, what actually happens is that the bank holding the offending value gets locked and its data is written out to the L2, the operation is performed at the ROP and the result written back, with the bank being unlocked afterwards.
You also need to look at ROP throughput in graphics tasks, which is also eerily close to the rates we're seeing, or more specifically to what happens when doing blends on a 32-bit Integer render target – that's pretty much an atomic op right there, and explains the performance we measured. In contrast to this, ATI actually opted for putting dedicated hardware into their shared memory implementation, handling everything involved from conflict analysis to the actual op, and it shows.
The reason why performance with Counters or Append/Consume buffers in D3D looks comparatively bad is tied to this as well: ATI has some in-hardware tweaks for those usage scenarios, making extensive use of the GDS, which also has hardware for atomics, mind you, which is perky since counter management is also pretty much an atomic op, and some dedicated pathways. That's in contrast to NVIDIA, who seem to have opted for a fully generic path. It's clearly up to discussion as to which design options are the best going forward, or how relevant these peculiarities will end up being, but we've already seen glimpses of the atomic performance difference having an impact (see [Lauritzen et al, 2010] for details).