FP64 Implementation Details
As we previously mentioned, GT200 also adds some CUDA-specific software features. The most obvious of them all is double precision (FP64) support, and the following slide nicely summarizes NVIDIA’s implementation:
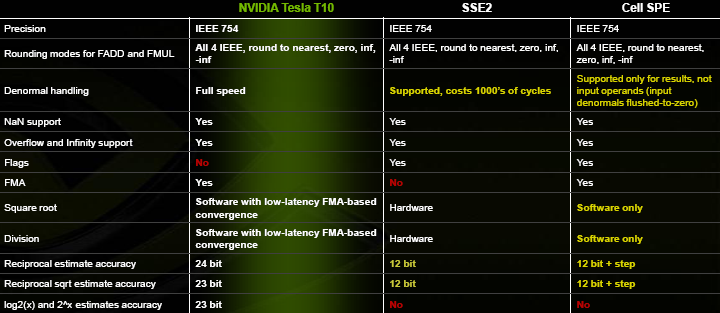
It’s very important to understand that this comparison is not valid for FP32, which still doesn’t handle denormals, underflow, or rounding towards +INF or –INF. Apparently, it’s pretty hard to find a developer who thinks that’s a problem too; most of the time, this level of compliance is more than enough for them and the only thing that really matters is performance.
While this level of compliance is not absolutely necessary for FP64 either, it is still much more appreciated by developers that need that level of precision in the first place, especially scientists. It’s likely to make a few applications possible, as well as make programming a bit easier since you won’t have to think about avoiding scenarios with possible denormals. How big of a deal is it precisely? Who knows, really; we’ll let the future determine that for us.
This implementation does have a clear hardware consequence, however: instead of reusing the same FP32 units over 4 cycles to get one FP64 result, NVIDIA designed discrete double precision units. The GT200 has one of them for every 8 FP32 units; they follow the all-new IEEE754r standard, including its suggested implementation of a fused multiply-add operation that can actually deliver better precision than the alternatives by not rounding the results after the multiplication.
In terms of FP64 performance, this means 1/12th the peak GFlops if you consider that the FP32 pipeline’s MADD and MUL units are now both fully usable. However, in real-world scenarios NVIDIA claims performance can be nearer 1/4th because the unit very often runs at full utilization with everything else being so fast relatively speaking that it’s very rarely bottlenecked. Of course, that’s really just saying that it’s fast... because it’s really slow. It’s still nothing to brag about though and quarter-speed DP by reusing the FP32 units would remain substantially faster.
However, it would be incorrect to claim that this is a technically inferior solution. First of all, it’s the only sane way to get this level of IEEE754r compliance. Secondly, the perf/mm² and perf/watt characteristics aren’t quite as undesirable as it might appear on first glance. You can’t just implement FP64 in four cycles on a vanilla FP32 unit; without getting into the details, you need a ‘27-bit multiplier/53-bit adder/11-bit exponent’ unit instead of a plain ‘24-bit multiplier/32-bit adder/8-bit exponent’ unit.
Therefore, it is likely that NVIDIA’s approach is at least as cheap as the more traditional quarter-speed implementation. It’s slower, of course, but it can be scaled both downwards and upwards: according to our sources, the only future GT2xx discrete chips on 55nm will be a shrink of GT200 and an ultra-low-end chip; the latter will nearly certainly not sport a DP unit.
Furthermore, on 40nm, it is likely that the chip being reused for Tesla will have 2 DP units while all the other ones will have only one. Therefore, the part of the line-up where DP performance doesn’t matter will likely ‘waste’ fewer transistors on double precision than is required with the quarter-speed approach, while the one chip where it does matter will ‘waste’ more but achieve higher levels of compliance. So as for why they chose to only implement one DP unit on GT200, it is important to realise that by the time they could be generating real revenue based on this, they’ll already have moved on to the 40nm Tesla generation with a higher ratio; this generation is for double precision prototyping, not deployment.
In terms of perf/watt, the DP unit is very likely clock gated so that it doesn’t waste dynamic power when idle in graphics mode. We were told leakage (which clock gating doesn’t stop) can now represent nearly half the overall power consumption however, so while it’s probably still more power efficient to have one FP64 unit idle than eight FP32 units waste their DP-specific hardware, it’s unlikely to be a massive difference.
It is worth pointing out that the way we are approaching this discussion is definitely from a GT200-centric point of view. If your base architecture is different, it is possible that other very interesting trade-offs (in terms of implementation and performance, not compliance) could be made, and we will discuss those in due time. For now, let’s simply conclude by saying that there is no reason to feel that NVIDIA’s implementation is in any way botched or inherently suboptimal.