
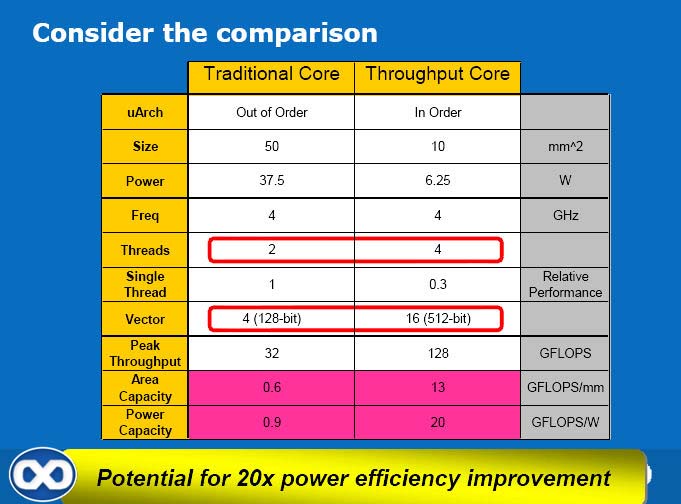
Now the clues as to where Intel's VCG are going with their graphics architecture appear. You're asked to visualise an in-order 4-thread 'throughput' core at 10mm2 and consuming only 6.25W. In theory, that'd look like a pretty weak CPU, with less than one third the single-threaded performance of current processors. The catch, however, is that they'd strap on a super-wide Vec16 FPU! It would likely be programmer-controlled via new instructions, so you'd use it as you see fit, but for graphics it would make some sense to think of it as working on scalar operations for four quads (2x2 pixels) at a time.
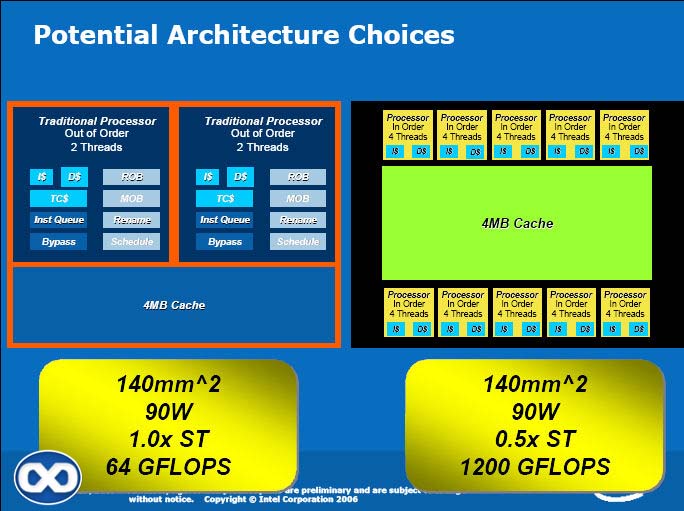
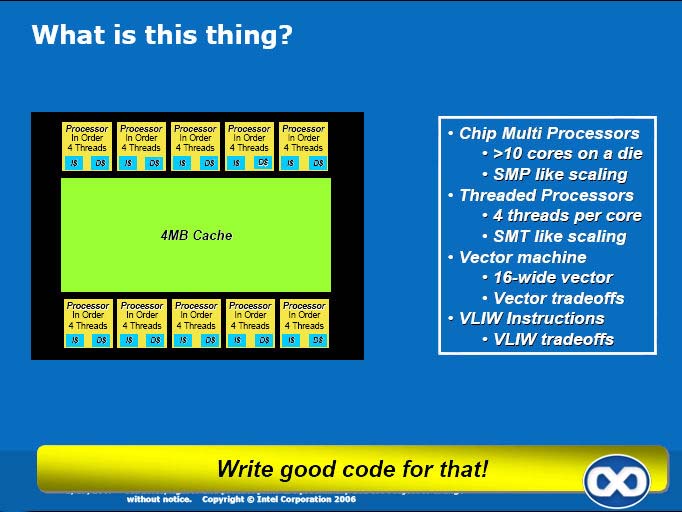
Now, pack a given die area with enough of those small cores, Intel says, and et-voila, a multi-threaded, very-wide vector processor that scales according to understood CMP and CMT ideology. But it's also one that might require very significant compiler and software engineering effort to run fast, given what we know of current CPU and GPU architectures.
It should once again be noted that each throughput processor would have ~30% the performance of a traditional CPU for single-threaded code, according to the slides, but for only 1/5th of the area even though it hosts a Vec16 unit. So again, the scaling opportunity of an architecture like that seems somewhat promising, even if not all applications it could run fully exploit the new FPU. Legacy code obviously wouldn't benefit at all from it.
So the question is, does the core support x86 instructions at all? If single-threaded performance is still roughly acceptable, it might make some sense for it to do so, and then you could think of the Vec16 FPU as an 'on-core' coprocessor that exploits VLIW extensions to the x86 instruction set. Or, the entire architecture might be VLIW with absolutely no trace of x86 in it. Obviously, this presentation doesn't give us a clear answer on the subject. And rumours out there might just be speculating on Larrabee being x86, so that doesn't tell us much either.

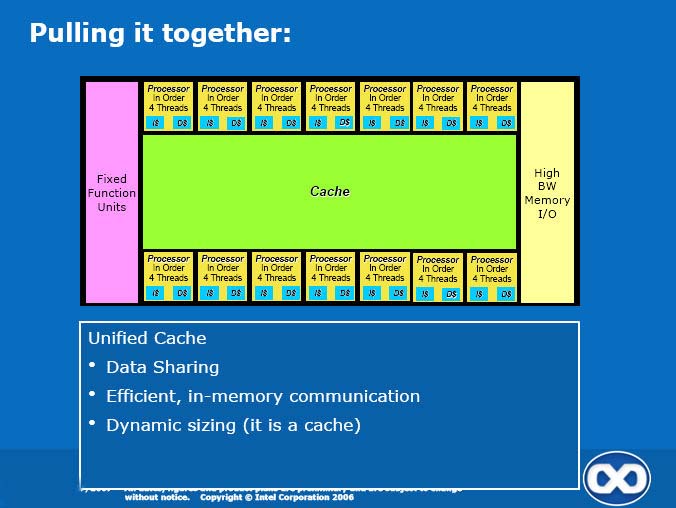
Add in thread synchronisation, cross thread communications and a completely shared cache setup and threads have an efficient means to communicate while processing. It does look quite different from what Intel is researching with Polaris aka the Terascale Initiative, but that doesn't mean it couldn't be quite efficient indeed. That remains to be seen, of course.
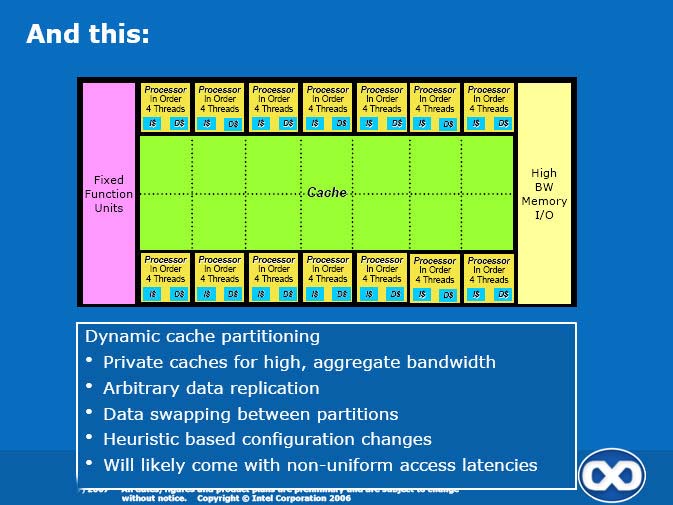
The slides do mention fixed-function units, but that doesn't really mean much, and it's hard to say how much of a focus Intel will have on implementing those blocks efficiently - especially so since these would be unused during non-graphics processing, and the previous slides clearly pointed out the advance of GPGPU as one of the key reasons behind the development of this new architecture for Intel.
It is not unthinkable that Intel would try to maximize the amount of work done in these processors, rather than in fixed-function units. For example, many of the operations achieved in the ROPs, such as blending, could be done there. Triangle setup wouldn't be too hard either. But what about rasterization, antialiasing, texture addressing and anisotropic filtering, etc.? There's more to a good graphics processor than big SIMD units and high aggregate bandwidth but it's a big step in the right direction, obviously.
And it's not like the described architecture would really be a traditional GPU anyway, with only 4 threads per core (arguably, that should be compared to G80's 12 warps/multiprocessor) and a huge cache! Either way, it will be quite interesting to see what Intel comes up with for the "fixed-function units" part of the chip. If it's good enough, this might be a real competitor in the 3D space. Otherwise, it'd likely only compete for GPGPU mindshare.