How Many Shaders?
Seeing as R580 is a product refresh it is fundamentally still based on the R5xx architecture, so for the most part they share a lot of the same configuration and functionality, with a Shader Model 3.0 basis. For more information on the R5xx architecture, take a look at our ATI R520: Radeon X1800 article.
Although it wasn't obvious with R520 and RV515, with the R5xx architecture ATI increased the flexibility in terms of the number of operating units within the pipelines. While their shader processors always had decoupled math ALU from texture addressing and sampling, the texture process groups previously always served a single quad of pixel shaders. However, as became obvious with RV530, ATI had changed the structure such that larger groups of ALU's could share texture processing groups and as such RV530 has 4 texture processors serving 12 shader processors. This is primarily where R580 differs from R520:
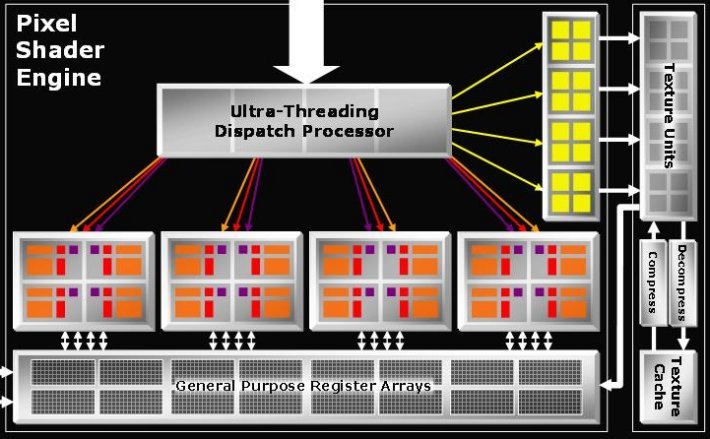
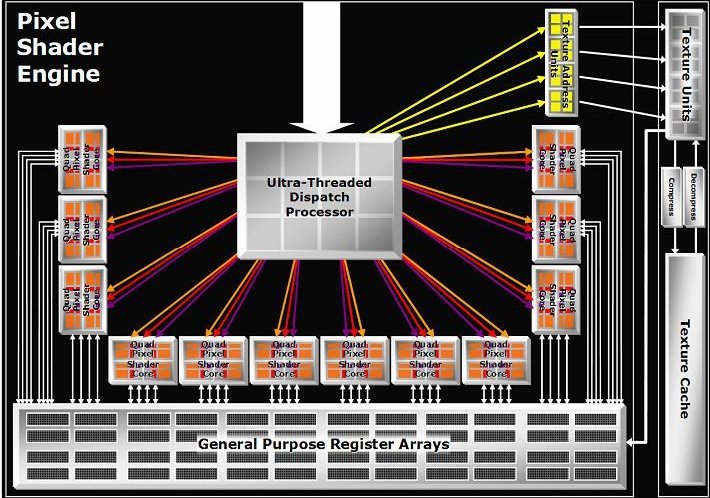
As can be seen from the diagram above, the primary difference between R520 and R580 lies in the number of pixel shader units available to each of them, with R520 having 16 pixel shader cores, while R580 triples that number. As is the case with all of the R5xx series, each pixel shader core consists of:
- ALU 1
- 1 Vec3 ADD + Input Modifier
- 1 Scalar ADD + Input Modifier
- ALU 2
- 1 Vec3 ADD/MUL/MADD
- 1 Scalar ADD/MUL/MADD
- Branch Execution Unit
- 1 Flow Control Instruction
The net result is that R580 contains 48 Vector MADD ALUs and 48 Vector ADD ALUs operating over 48 pixels (fragments) in parallel. Along with the pixel shader cores, the pixel shader register array on R580 has also tripled in size in relation to R520, so that R580 is still capable of having the same number of batches in flight.
The R580 diagram above isn't entirely accurate, as it indicates that there are 12 different dispatch processors for R580, where R520 has 4 - this is, in fact, not the case. As with RV530, R580's "quads" (or lowest element of hardware scalability in the pixel pipeline) have increased such that they can handle three quads in the pixel shader core, but they do so by operating on the same thread. The net result is that R580 still contains 4 different pixel processing cores, ergo only 4 dispatch processors, with each core handling up to 128 batches/"threads". As a result, R580 is still handling a total of 512 batches/"threads" as R520 does. Each of the batches in R580 consist of a maximum of three times as many pixels (48), so that they can be mapped across the 12 pixel shader processors that exist in each of the 4 cores, with the net result being that R580 can have 24,576 pixels in flight at once. Note that because this is still based around 4 processing cores, the lowest level of shader granularity is likely to be 12 pipelines, so if ATI releases parts that's had failures within the pixel pipeline element of the die the next configuration down would likely be 12 textures, 36 shader pipelines, and 12 ROPs.
ATI have also increased the Hierarchical Z buffer size on R580, which can now store up to 50% more pixel information than R520 can, allowing for better performance at even higher resolutions. However, other than that most of the other elements stay the same, shader wise, with R580 still having 8 vertex shaders, single Z/Stencil rates (unlike RV530) and still continuing with 16 texture units serving all 48 shader processors.
R580 shader core FLOPs
| Instruction | FLOPs | Components | Total FLOPs | |
| PS ALU 1 | 48 ADDs | 1 | 4 | 192 |
| PS ALU 2 | 48 MADDs | 2 | 4 | 384 |
| VS ALU | 8 MADDs | 2 | 5 | 80 |
The table above breaks down the number of floating point operations that the R580 can handle per-cycle, which adds to 656 FLOPs per cycle. When this is applied to the clockspeed of 650MHz it equates to 426.6GLOPS/s of floating point programmable math processing power in a single graphics board. When the graphics vendors apply processing capabilities such as texture addressing and shader interpolation this total, they will say, exceeds 500GFLOPS/s. 1 TFLOP of processing power was once held as a nirvana for high end super computers, and yet with dual graphics becoming increasingly common, here we are today with the capability of 1TFLOP/s of processing power in our PC's....and its primary use is to push pixels in games like Doom3!
We've quizzed ATI's Engineering over design of R580 and the reasoning behind it in are short interview here.