Dragons, triangles, conflicts and......
There's no arguing that the Heaven demo put together by the Unigine guys is the most flamboyant user of DX11 tessellation currently available (SDK samples don't count). It's the triangular equivalent of "Girls gone wild", and, more importantly, after having had the honour of being the star of the Fermi Graphics "reveal", it's become a topic of debate and interest all across the intertubes. So we absolutely had to take it on a second date, after the one from a few pages ago, going deeper this time.
As you've seen, turning on tessellation in Heaven incurs a rather hefty performance penalty - the question is why? What's hurting Cypress so significantly here? The only way to somewhat pertinently answer that was to profile one of the sticking points in the benchmark, and look at the story that the GPU's performance counters told. In an unexpected twist of fate, ATI's PerfStudio actually worked nicely and allowed us to do just that. Finding the stickiest sticking point was also quite easy. Behold:
As you've seen, turning on tessellation in Heaven incurs a rather hefty performance penalty - the question is why? What's hurting Cypress so significantly here? The only way to somewhat pertinently answer that was to profile one of the sticking points in the benchmark, and look at the story that the GPU's performance counters told. In an unexpected twist of fate, ATI's PerfStudio actually worked nicely and allowed us to do just that. Finding the stickiest sticking point was also quite easy. Behold:

We always knew that it took tessellation to make staring up a stone dragon's.....well, you know, more enjoyable (yes, the screen-grabs aren't perfectly identical...whoops). That being said, in this spot, performance is extremely low, and is almost resolution independent, which is a first indication that it's not rendering the pixels that's clogging Cypress's tubes. In fact, here's the breakdown of GPU time/state for the tessellated case:
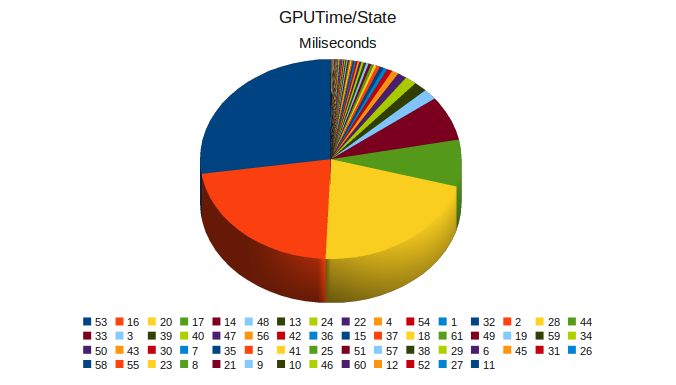
There are 61 states that are successively set in order to generate the final frame, but from those 61 states, the GPU spends 85% of its time on 5, namely states 53, 16, 20, 17 and 14, out of which the first 3 alone require 71% of the render time.
Looking more carefully, we noted that these 5 states account for most of the tessellation done in the scene (most others have null hull and domain shaders,. Looking at the time allocation per each shader type, the domain shader takes the lion's share of ALU time. This is hardly surprising once we take into acount that the for states 53, 16 and 20, for example, there are 1.6, 1.1 and 1 million vertices going into the domain shader from the tessellator (the demo also does displacement mapping, so they also sample from a displacement map in the domain shader, adding some texture load too).
Moving onwards from the domain shader, we find that, on average, for 15% of the render time the pipeline is stalled by rasterisation (setup included here), meaning that the domain shader can output processed vertices and the primitive assembler can assemble them faster than they can be setup and rasterised. This is a consequence of having numerous small triangles in the scene (just look at something like the dragon's leg or the roof), and is one of the cases where upping setup rate beyond 1 triangle/clock could have helped (we're pretty sure the rasteriser itself isn't the one causing the stalls, given pixel/triangle ratios). One thing worth noting is that between 60 and 80(!)% of these primitives get culled, which doesn't strike us as terribly efficient: you've just hammered the GPU with some heavy tessellation, generated a sea of triangles out of which a huge portion won't be used since they're back facing, or 0 area for example. It's a clear indication that performance must be traded for final image quality with tessellation, as with any other facet of real-time graphics.
Finally, there's one extra systemic effect that we've noticed: the appearance of stalls caused by the LDS. As you know, for Cypress attribute interpolation has been moved to the ALUs, with attributes being stored in the LDS for quick retrieval. In the non-tessellated case there are no such conflicts, but adding tessellation and thus increasing the count of primitives across which attributes need to be interpolated generates quite a few of them, adding to the cost. Now, from what we've seen in practice (and what others have shown us), ATI's compiler is not quite adept at generating optimal access patterns for the LDS (in fact, the opposite is closer to being true), and, as such, we'd expect some improvements to happen here over time, easing the hit. The rest of the rendering process is nothing special, so we won't dwell on it here (but perhaps in another piece, which will be entirely devoted to such analysis).
Overall, putting things together, this little experiment has helped us gain a wee bit of insight into what makes Heaven's implementation of tessellation be so costly on Cypress (and we'll go out on a limb to say it won't be free on other architectures either, although we'd love to be proven wrong). The impact is multi-dimensional, since the huge increase in vertex count post-tessellator turns makes the domain shaders quite expensive (they're run on a per-vertex basis), the generation of triangles smaller than 16 pixels (in the raster pattern Cypress employs of course) makes the Cypress' rasteriser function sub-optimally, and the increase in interpolation requirements causes LDS access contention.
There are also a few other insidious effects, like the increase in Z/stencil work (we've measured it as well), coupled with a slight reduction in hierarchical-Z efficiency, but these are lighter when compared with the primary effects. We expect a bit of extra performance to come via subsequent compiler tweaks and driver updates, but not wads of it. We also have doubts that what Heaven does with tessellation is a realistic option for games in the near future. By the time such extensive use of it will be needed/common case, we'll probably be looking at new architectures from both IHVs (heck, there may even be a third one by then!), that are engineered to solve most if not all problems that come with very large triangle counts and small resulting (perhaps sub-pixel) triangles et al.
There are 61 states that are successively set in order to generate the final frame, but from those 61 states, the GPU spends 85% of its time on 5, namely states 53, 16, 20, 17 and 14, out of which the first 3 alone require 71% of the render time.
Looking more carefully, we noted that these 5 states account for most of the tessellation done in the scene (most others have null hull and domain shaders,. Looking at the time allocation per each shader type, the domain shader takes the lion's share of ALU time. This is hardly surprising once we take into acount that the for states 53, 16 and 20, for example, there are 1.6, 1.1 and 1 million vertices going into the domain shader from the tessellator (the demo also does displacement mapping, so they also sample from a displacement map in the domain shader, adding some texture load too).
Moving onwards from the domain shader, we find that, on average, for 15% of the render time the pipeline is stalled by rasterisation (setup included here), meaning that the domain shader can output processed vertices and the primitive assembler can assemble them faster than they can be setup and rasterised. This is a consequence of having numerous small triangles in the scene (just look at something like the dragon's leg or the roof), and is one of the cases where upping setup rate beyond 1 triangle/clock could have helped (we're pretty sure the rasteriser itself isn't the one causing the stalls, given pixel/triangle ratios). One thing worth noting is that between 60 and 80(!)% of these primitives get culled, which doesn't strike us as terribly efficient: you've just hammered the GPU with some heavy tessellation, generated a sea of triangles out of which a huge portion won't be used since they're back facing, or 0 area for example. It's a clear indication that performance must be traded for final image quality with tessellation, as with any other facet of real-time graphics.
Finally, there's one extra systemic effect that we've noticed: the appearance of stalls caused by the LDS. As you know, for Cypress attribute interpolation has been moved to the ALUs, with attributes being stored in the LDS for quick retrieval. In the non-tessellated case there are no such conflicts, but adding tessellation and thus increasing the count of primitives across which attributes need to be interpolated generates quite a few of them, adding to the cost. Now, from what we've seen in practice (and what others have shown us), ATI's compiler is not quite adept at generating optimal access patterns for the LDS (in fact, the opposite is closer to being true), and, as such, we'd expect some improvements to happen here over time, easing the hit. The rest of the rendering process is nothing special, so we won't dwell on it here (but perhaps in another piece, which will be entirely devoted to such analysis).
Overall, putting things together, this little experiment has helped us gain a wee bit of insight into what makes Heaven's implementation of tessellation be so costly on Cypress (and we'll go out on a limb to say it won't be free on other architectures either, although we'd love to be proven wrong). The impact is multi-dimensional, since the huge increase in vertex count post-tessellator turns makes the domain shaders quite expensive (they're run on a per-vertex basis), the generation of triangles smaller than 16 pixels (in the raster pattern Cypress employs of course) makes the Cypress' rasteriser function sub-optimally, and the increase in interpolation requirements causes LDS access contention.
There are also a few other insidious effects, like the increase in Z/stencil work (we've measured it as well), coupled with a slight reduction in hierarchical-Z efficiency, but these are lighter when compared with the primary effects. We expect a bit of extra performance to come via subsequent compiler tweaks and driver updates, but not wads of it. We also have doubts that what Heaven does with tessellation is a realistic option for games in the near future. By the time such extensive use of it will be needed/common case, we'll probably be looking at new architectures from both IHVs (heck, there may even be a third one by then!), that are engineered to solve most if not all problems that come with very large triangle counts and small resulting (perhaps sub-pixel) triangles et al.