Analysis: Triangle Setup (Or Why A 4-way Is Only For The Rich Or The Daring)
Triangle setup is one of the questions that has had our attention for a long stretch of time, ever since Fermi got initially announced. Prior to actually having hardware on hand, we relied on help from a friend (thanks Dean!) to run some custom tests on a GTX 480 to see what's what. Armed with the knowledge gained from that early experience, we iterated a few times until we reached a satisfactory test setup, and a moderately satisfactory level of knowledge.
What we do rendering wise is deceivingly simple: we render a screen filling mesh (ResolutionX x ResolutionY sized) that we tessellate based on the triangle area we desire to check. The mesh lives in the Oxy plane in object space, and gets orthographically projected into screen-space (thus we ensure that we're actually getting the screen-space triangle area that we want). It's nicely uniform, with all triangles being congruent.
There are two possible test cases that we use the mesh for: we either fully tessellate on the host side, at mesh instantiation, which basically means subdividing it into congruent quads (area for 1 quad equals two times the desired triangle area, since there are two triangles per quad) and then building the index list. In this case we also pass the mesh through a D3DX10Mesh->Optimize step.
The second case involves using GPU tessellation, which means that on the host side we coarsely subdivide the screen filling mesh into quads (area for 1 quad = (2 * i * i) * desired triangle area, where i represents the tessellation factor), and then finely tessellate the quads on the GPU, using the adequate tessellation factor (we use quad patches since they produce a nice, even pattern). The process is a bit more involved, but we doubt you're all that interested in knowing more.
For each case there are two sub-cases, namely rendering only with Z enabled, thus getting only depth interpolated across the tris during setup, or rendering with a varying number of attributes interpolated across the tris, which get returned in the pixel shader. We use instancing to draw the mesh multiple time with minimal overhead, and then rely on the D3D query mechanism to get data back about the rendering process (depth test is set to always). With that said, let's first look at what happens when we tessellate on the host side (we've also thrown in an 8800GT for a glimpse at how things used to be):

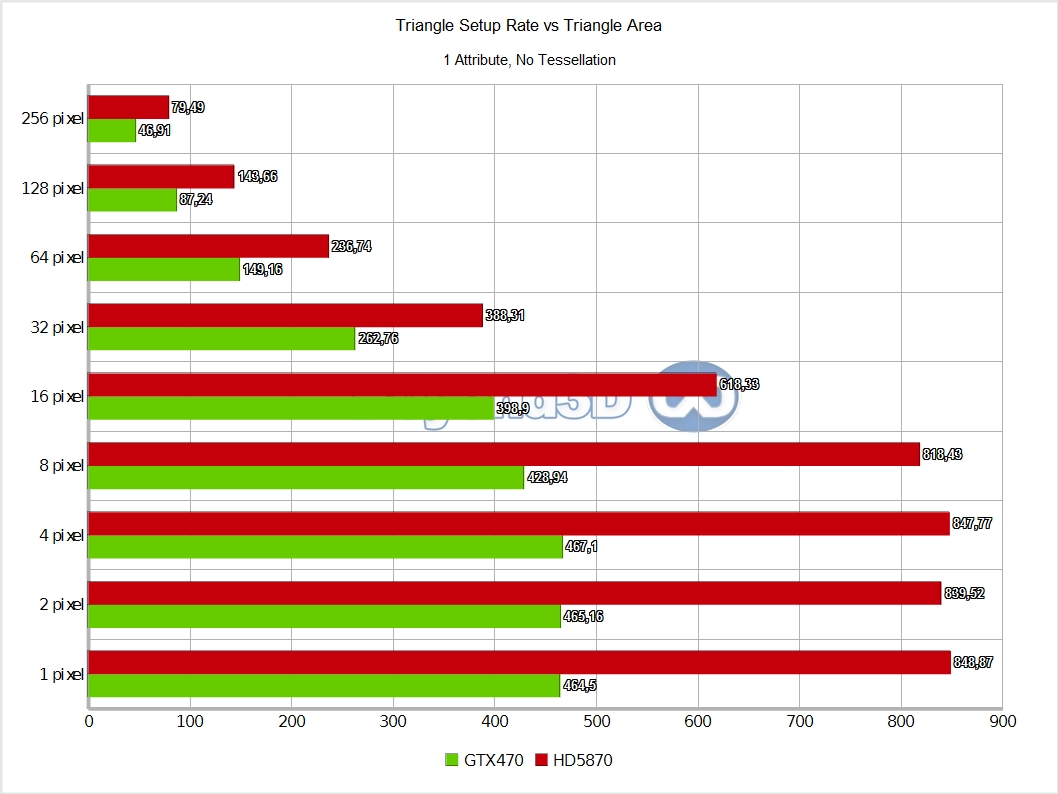
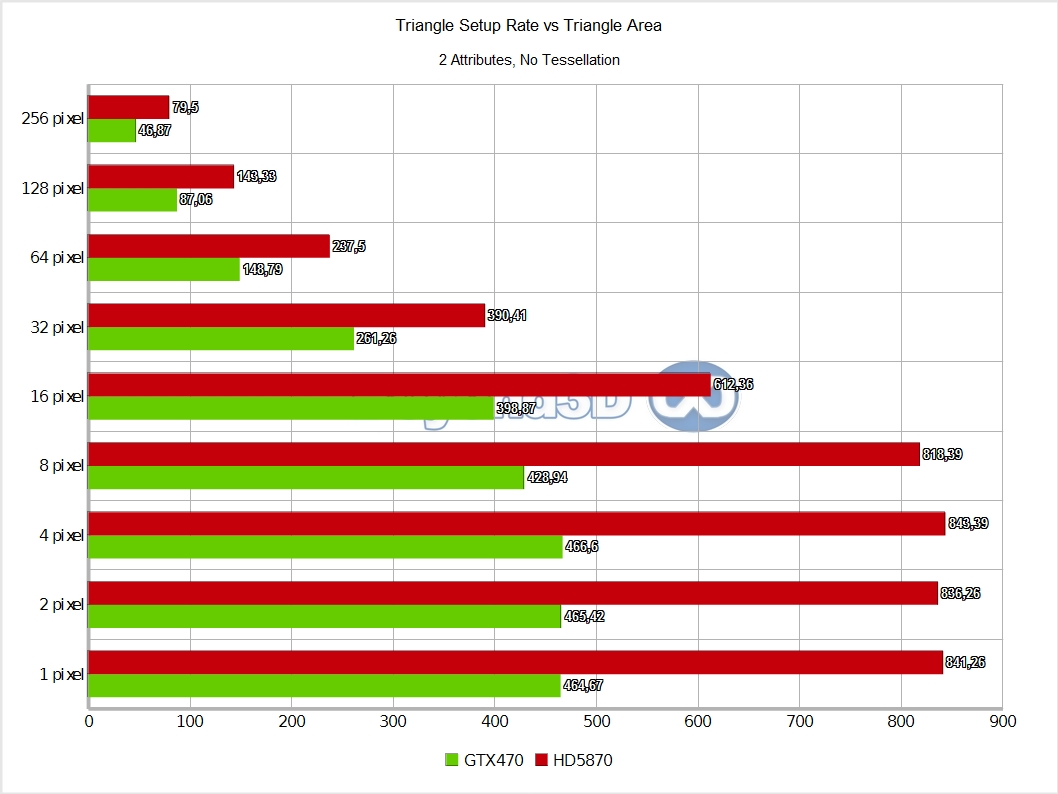
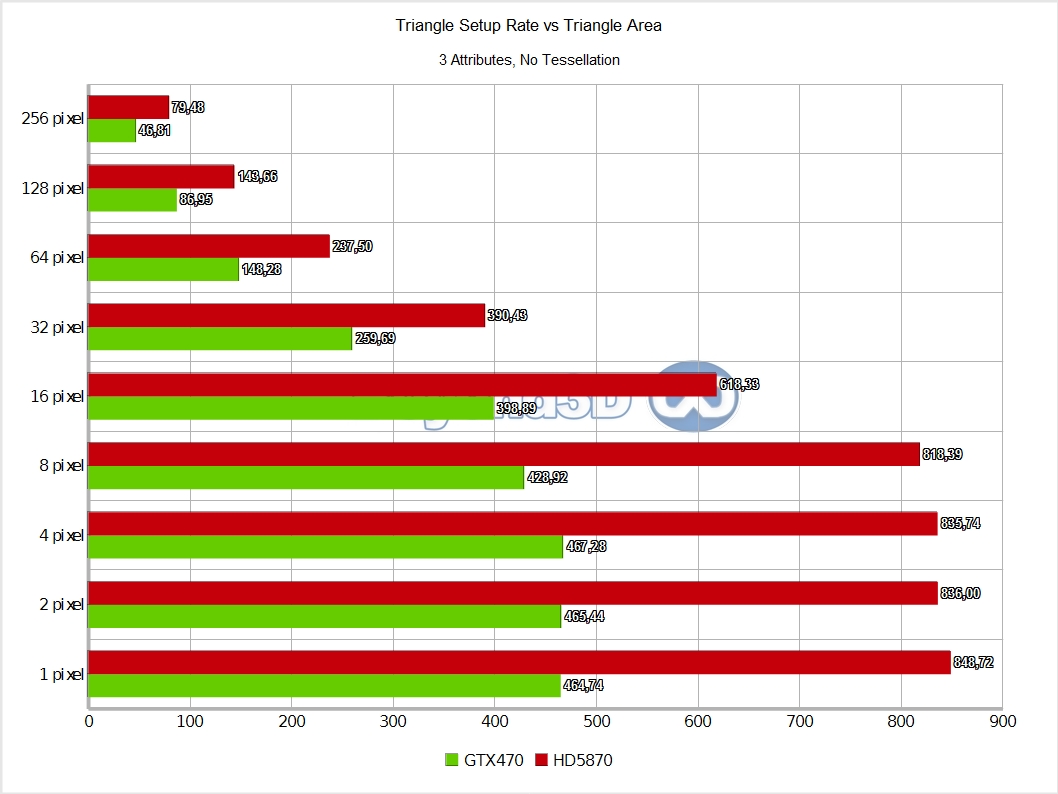



First shock : Fermi looks as if it's doing slightly under 1 triangle per clock, or, wording it differently, reaching less than 25% efficiency (the fact that G8x/G9x are 2 clocks per triangle architecture should hardly surprise anyone by now). The Z-only case is likely to be the closest we can get to isolating the setup part (VP transform, coverage determination, interpolant calculation), since attribute interpolation is simpler and has a diminished impact.
Even so, larger triangle sizes are impacted by it as the bottleneck moves towards that end of the process, and no buffering is infinite (also, triangles start crossing screen tiles, thus inducing further inefficiencies as work gets replicated). Cypress handles itself decently by comparison, but it's quite interesting to look at how the two architectures handle interpolating progressively more attributes: Slimer has no preference with regards to either interpolating 4 Float attributes or using the system value mechanism, namely SV_Position (also 4 Floats), whereas Cypress dislikes it.
This hints at Cypress having to go through a slow path in this particular case (or rather, it hints at the existence of a small dedicated cache/buffer for system values, that gets thrashed with larger triangle sizes as the bottleneck shifts towards the last stage of rasterisation).
It also appears that Slimer is marginally better with attribute interpolation overall. All of the above is an important datapoint since an en-vogue theory was that small triangles kill Cypress and empower Slimer – this doesn't seem to be the case. But maybe not all triangles are the same:
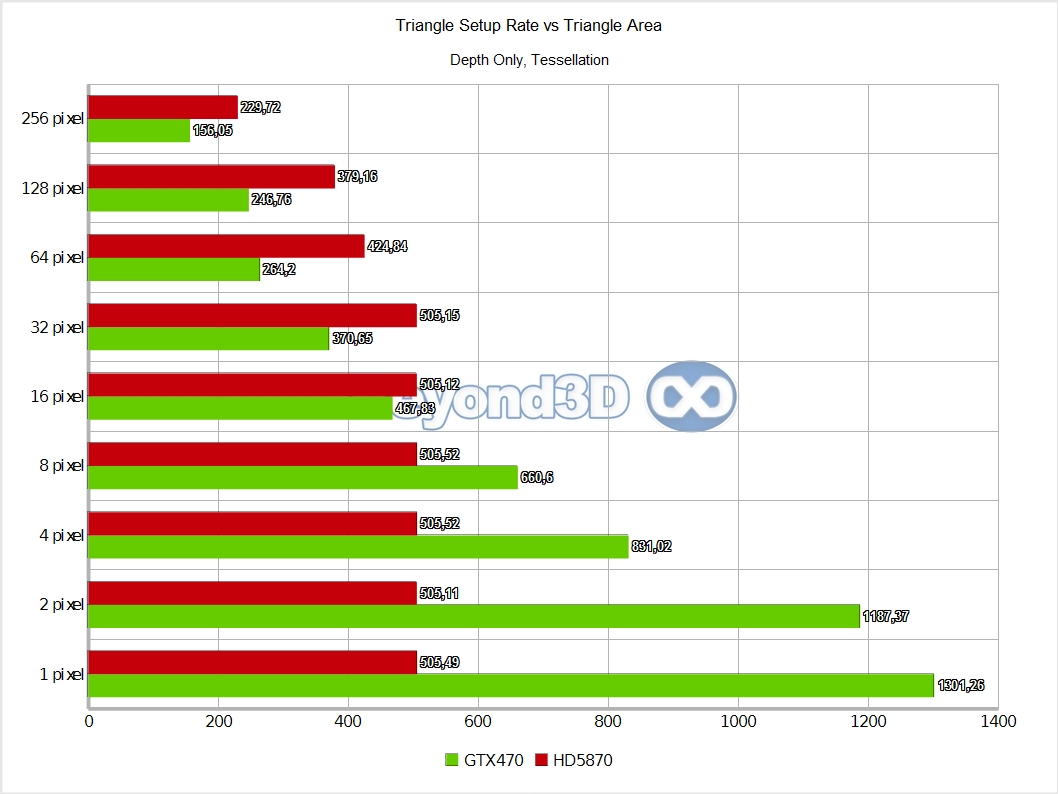
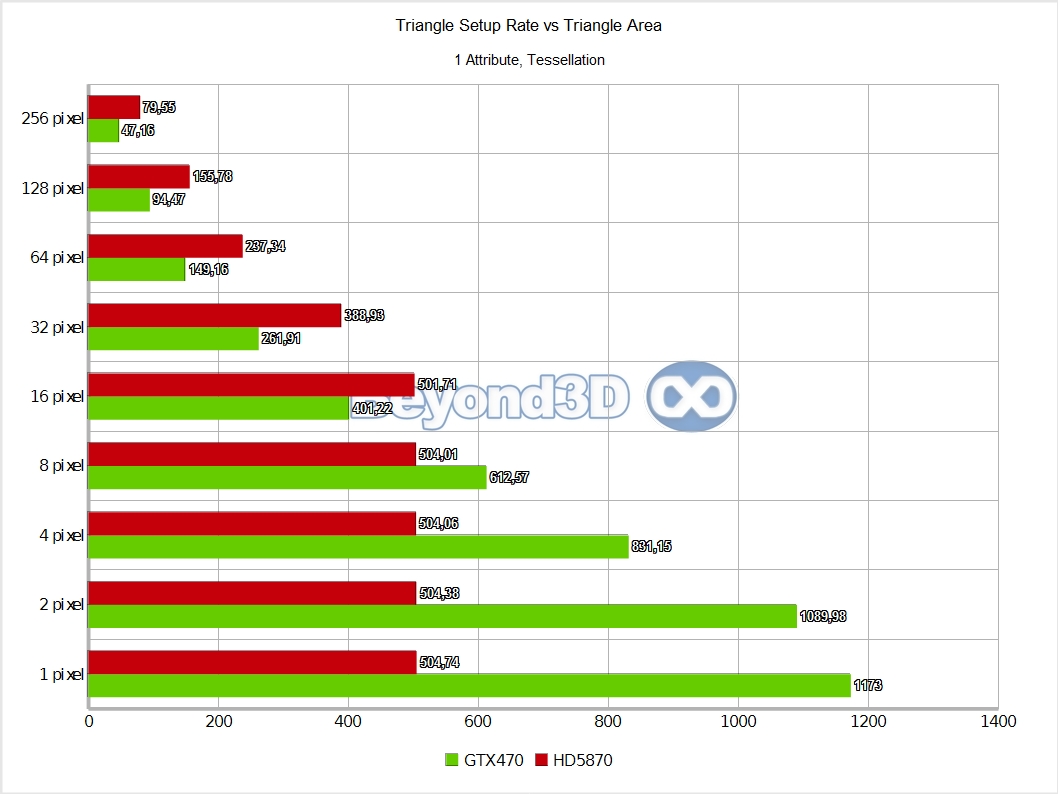
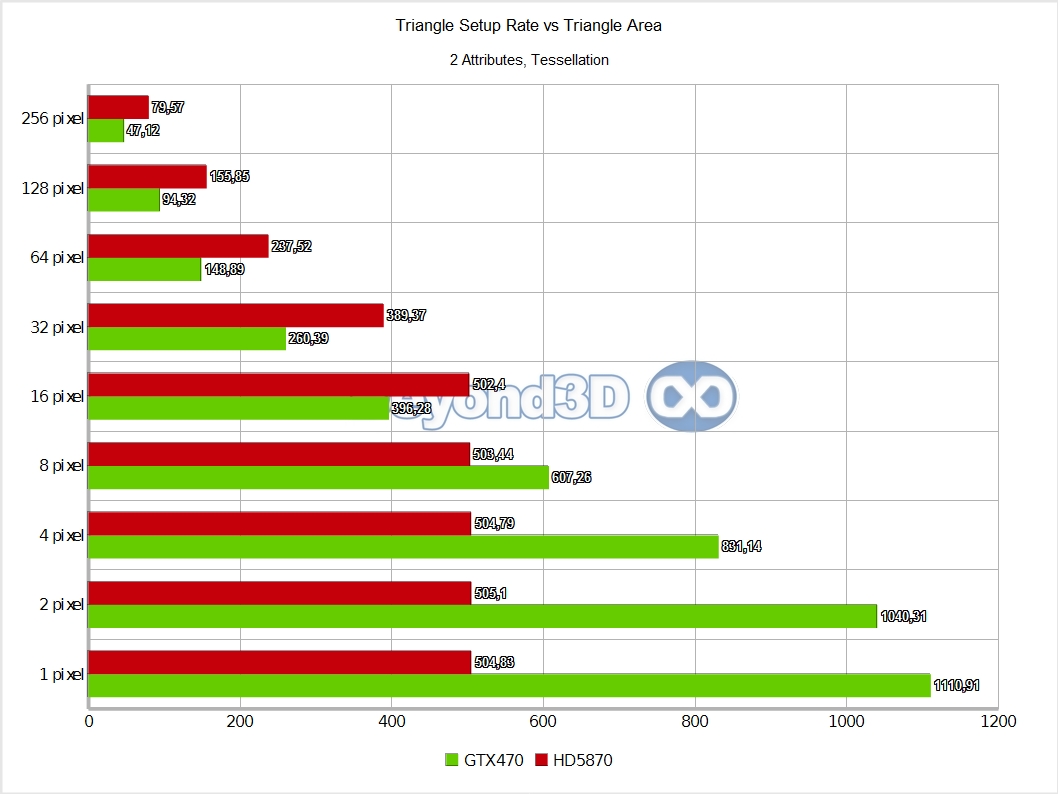


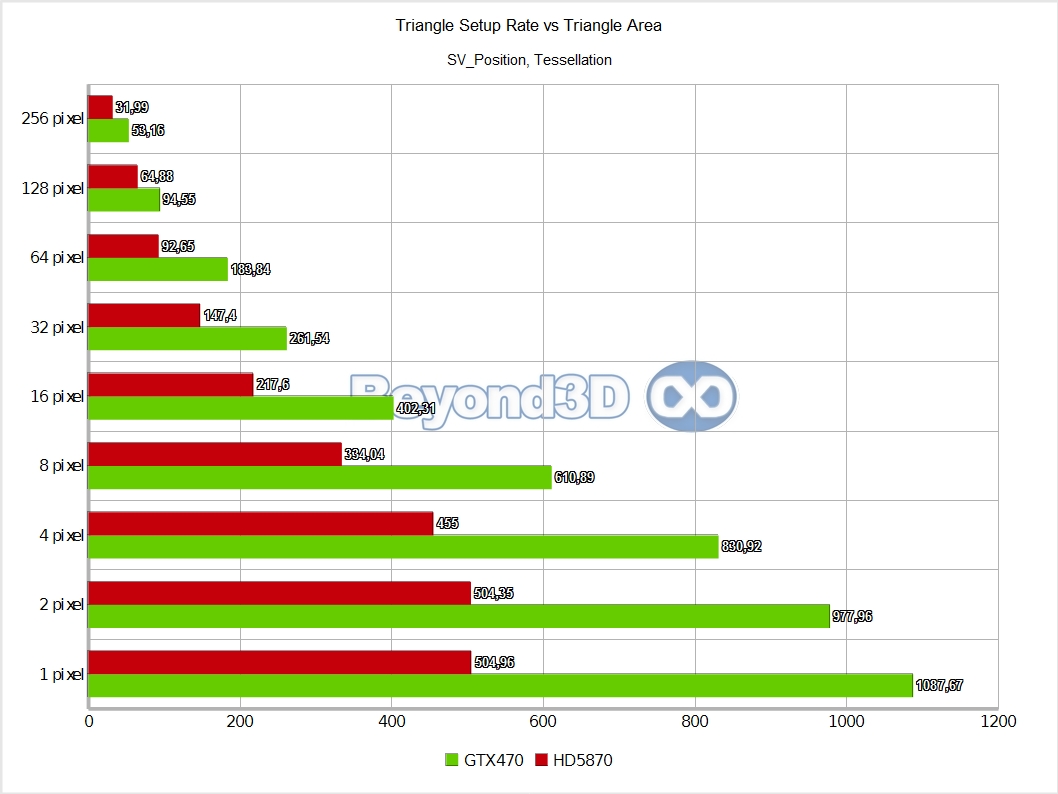
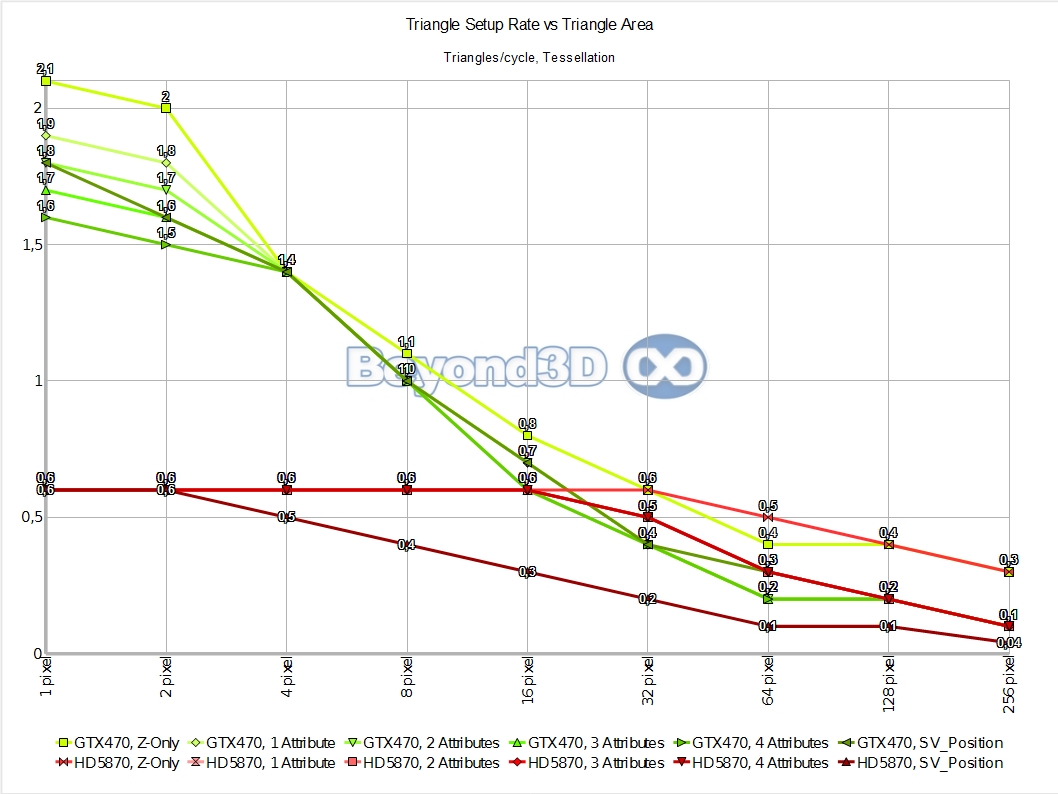
Hello, parallel setup, welcome! This is considerably more in touch with what marketing slides left and right have been showing – between 1.8 and 2.1 triangles per cycle is pretty nifty, if still a bit far from the theoretical count of 4. Data routing has its cost, and the more data that needs to be re-shuffled, the lesser achieved performance, so for extremely fat vertices/control points, even less parallelism can be achieved.
When we look at the competition, it's even better: up to 2.57 times faster, because not only does Slimer speed up, but also Cypress slows down. There's a currently running meme about Cypress taking 3 clocks per tessellated triangle - this is incorrect in an absolute sense, albeit we can generate that scenario quite easily, as we can do a bit better than what you're seeing (note we've reached up to ~600 MTris/s by using triangular patches, thus trimming down the per control point data, all else being equal).
ATI's problem is primarily one of data-flow: they try to keep some data in shared memory (as far as we can see, they try to keep HS-DS pairs resident on the same SIMD, with hull shaders being significantly more expensive then domain shaders) but data to and from the tessellator needs to go through the GDS. There's also the need to serialise access to the tessellator, since it's an unique resource, coupled with a final aspect we'll deal with when looking at math throughput.
Given all this, fatter control points (our control points are as skinny as possible) or heavy math in the HS (there's no explicit math in ours, but there's some implicit tessellation factor massaging and addressing math) hurt Cypress comparatively more than they hurt Slimer - and now you know how the 3 clocks per triangle scenarios come into being, a combination of the two aforementioned factors.
Getting back to the main course, the question remains: why does Slimer need tessellation to expose its parallel setup capability? You may be thinking something along the lines of "bah, you guys are stupid, it's painfully obvious that the mesh data-set was too large, and caused vertex cache trashing/excessive fetches from VRAM". Whilst this line of reasoning is not without merit, we did struggle to be as un-stupid as possible – we tried rendering just a few tris of given size, but the result was well within noise margins.
In fact, we struggled with many potential theories, until a fortuitous encounter with a Quadro made the truth painfully obvious: product differentiation, a somewhat en vogue term over at NVIDIA, it seems. The Quadro, in spite of being pretty much the same hardware (this is a signal to all those that believe there's magical hardware in the Quadro because it's more expensive – engage rant mode!), is quite happy doing full speed setup on the untessellated plebs.
We can only imagine that this seemed like a good idea to someone. Sure, there's a finite probability that traditional Quadro customers, who are quite corporate and quite fond of extensive support amongst other things, would suddenly turn into full blown hardware ricers, give up all perks that come with the high Quadro price, buy cheap consumer hardware and use that instead.
Capping is done in drivers, by inducing artificial delays during the post viewport transform reordering (mind you this hasn't yet been confirmed by NVIDIA, but our own educated conclusion). Amusingly enough, Teslas get the cap too, in spite of qualifying for the "really fucking expensive" category as well. We'll refrain of arguing for or against the decision, since there are points to be made coming from either angle, and just stop at reporting it. That means it's time for maths!