Performance Estimates & Analysis
While GT200 only delivers about twice the theoretical floating-point performance of G80 (about 2.08x for the S1070 to be precise), NVIDIA claims they’ve often seen real-world improvements much larger than that:
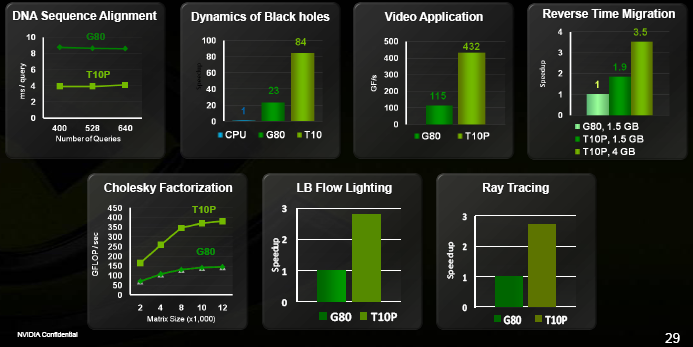
The numbers speak for themselves (we asked about the specific video & ray tracing algorithms being benchmarked, but they could only imply that neither was public). Interestingly, these developers haven’t had much time with the new chips yet, so NVIDIA did not believe new CUDA 2.0 features (which we’ll look at shortly) were used much if at all. These improvements are very much about the improved hardware performance and architecture.
So outside of the extra video memory, what makes this kind of performance scaling possible? Several factors, mostly:
- The ‘Missing MUL’: On G80, it wasn’t exposed at all for graphic. In CUDA, it was partially accessible: it was possible, although difficult, to extract half of its peak performance under certain circumstances resulting in a peak rate of 432GFlops. On GT200, it seems possible to achieve very near the peak rate in CUDA with few if any obvious scheduling limitations. In graphics, it’s a bit more complicated, but that is not this article’s subject…
- The register file per SM increased from 32KiB to 64KiB. There are multiple advantages to this; it makes it much less likely for the compiler to ‘spill’ registers to memory, allows for more threads to run at the same time to hide memory latency, and lets the compiler use more registers for its optimisation process. Apparently, spilling was pretty rare but it did happen in a few applications.
- In addition to full PCI Express 2.0 support, GT200 also allows for CUDA computations to occur at the same time as one-way data transfers to or from the GPU (as on G84/G86/G9x). So you’ve got two transfer modes: you can both send and receive data at the same time, or keep the ALUs busy while either sending or receiving data. This can drastically reduce the amount of time the GPU is idling when shuffling data around. In the next generation, two-way transfers will be made possible at the same time as computation. NVIDIA also seems very happy about the real-world throughput of their PCI Express implementation, which they claim is in excess of 6GB/s (or 75% of the peak).
- There’s now a memory coalescing cache in each memory controller partition. With G80, the threads in a batch/warp (or half-warp) had to have contiguous memory access patterns; otherwise, your bandwidth efficiency would drop proportionally to the number of different memory locations you were accessing. On GT200, the memory controller will try to intelligently combine memory accesses to improve efficiency. Don’t expect it to magically go as fast as the optimally contiguous case, but it should still help a lot and make the programmer’s job easier.