SciComp’s SciFinance: High computational requirements in the world of finance are often associated with derivative/option pricing; however, classic stock options with pricing being determined by the market are by far the most talked about. There’s another form of derivative though: those which are not traded on the market and only exchanged over the counter (primarily between financial institutions, hedge funds, etc.) – and pricing those is quite a different ballgame.
Traditionally, traders who imagined a deal talked to ‘quants’ (PhDs in mathematics or physics who are specialized in finance) and the mathematical equations they came up with for the pricing model then had to be transformed into a program through weeks of hand-coding. After this error-prone process, the program had to be run to estimate the price:
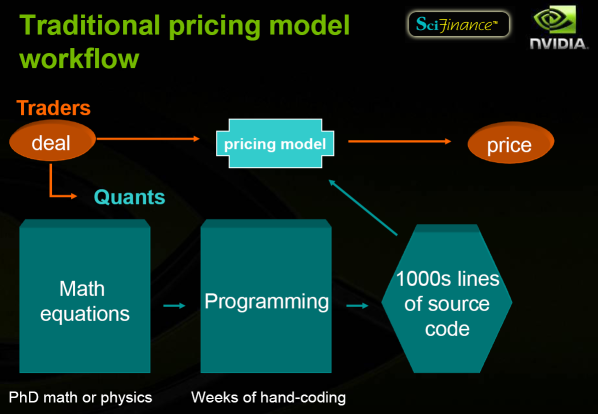
SciFinance’s approach is to automate program generation; instead of manual coding, the quants can ‘simply’ describe their equations in a specialized language. The process is much quicker and much more reliable. Therefore, the relative length of running the program increases and it becomes more of a bottleneck. The solution they came up with is, of course, FPGAs. Uhhh, wait, no, I meant CUDA obviously:
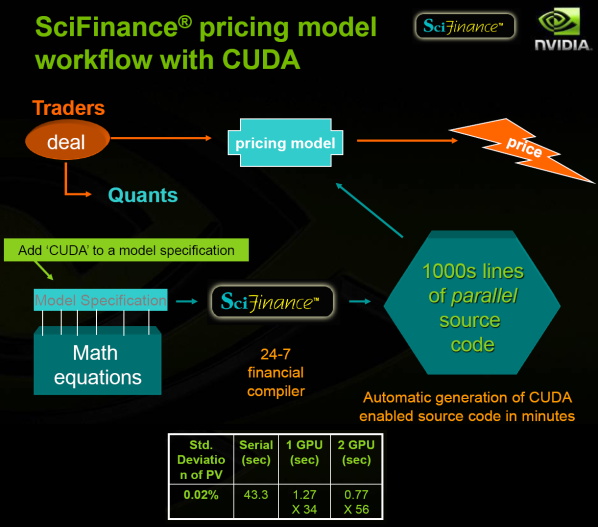
What may not be as obvious in that image is that the only thing you need to add to get GPGPU acceleration is literally ‘CUDA’; it’s a single keyword, not a fundamentally different way to formulate the math equations. This allows SciComp’s customers to save even more time while also improving accuracy (through a higher number of iterations), both of which result in obvious financial benefits.
The difference between merely being able to demonstrate the acceleration of a basic stock option pricing model and this is huge. The amount of work involved is likely ridiculously higher, and it’s a pretty good example of how much far along CUDA is in terms of software. As we mentioned previously, however, this business is extremely secretive so it’s basically impossible to tell who will be using SciFinance’s CUDA path and how many Teslas they might want to buy for it. We doubt it’s a huge business, but presumably it’s not that small either.
Jack Collins of the National Cancer Institute: The next presentation was an interesting but quite abstract one from Jack Collins, who one of the NVIDIA guys described afterwards as ‘someone who is very humble about it but who influences a lot of the US Government’s funding, especially in healthcare’. His focus is obviously on cancer research, and a good bit of his interest in GPUs was generated by AutoDock:

This slide actually wasn’t from the Editor’s Day presentation, but you get the point. Interestingly, he didn’t come with a vision of huge clusters that could simulate various processes incredibly fast; instead, he thought the more interesting aspect of GPGPU was by far the much higher level of performance it gives to individual researchers, whether they use Teslas or GeForces for their deskside machine. He thinks the productivity improvements coming from much shorter runtimes for small teams is the most likely to allow for a breakthrough.
Amitabh Varshney of the University of Maryland: Amitabh explained several potential applications of GPGPU for the academic community, from molecular dynamics to astrophysics, protein electrostatics and audio-based cameras. He was also very optimistic about its applicability to many aspects of climate modelling and nano assembly, both at the leading edge, now that double precision is supported.
We combined a slide from both Jack Collins and Amitabh Varshney in order to, in our opinion, nicely summarize the dynamics for the research community. It reminds us how hardware is only one small part of the cost for these applications, while also giving a optimistic outlook of the impact GPGPU can have thanks to its (relative to alternatives) attractive programming model and very low cost of entry.
