An RGSS Implementation
Rotated Grid Super-sampling (RGSS)can be implemented using an Accumulation Buffer technique and also by the 3dfx T-Buffer technology. We will detail step-by-step the implementation of RGSS utilizing the VSA-100 T-Buffer capability found in 3dfx 's recent Voodoo5 product offering:
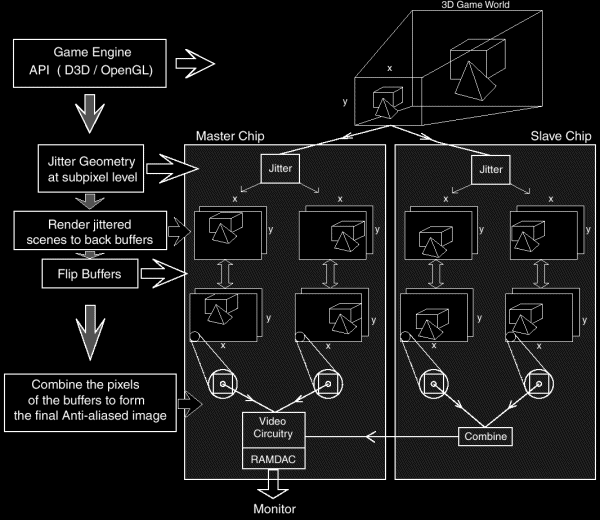
1. The game engine creates the 3D environment using a 3D API such as Direct3D or OpenGL. Both these APIs use triangles as their basic building block to create 3D objects. Each triangle has coordinates in 3D space. These coordinates are transmitted, transformed and lit. If hardware T&L is supported, of course, the data is sent directly to the video card 's T&L unit for transformation and lighting.
2. The 3dfx VSA-100 T-Buffer implementation uses a multi-chip solution where each chip calculates 2 sub-samples (it is safe to assume that in the future chips will allow for more sub-samples per chip).We thus need at least 2 VSA-100 chips to implement 4 sub-sample anti-aliasing. We'll assume a 2-chip configuration, such as the Voodoo5 family, in our explanation. As said before, the sub-samples are jittered or, more specifically, rotated. These jittered sample positions are obtained by shifting the geometry 's vertices. So for each sub-sample, the vertices receive a precise sub-pixel level perturbation that matches the targeted sub-sample positions. Figure 5 illustrates this. The sample position and resolution stays equal, but by moving the geometry at the sub-pixel level we get different equivalent sub-amples. These geometry shifts are handled in hardware in the VSA-100 chip, so there is no software overhead required for RGSS anti-aliasing.
3. Now all the shifted geometry is rendered. Each shifted version is sent to its own T-Buffer. Each T-Buffer has the same resolution as the final anti-aliased image. The number of buffers is equal to the number of sub-samples taken. Each VSA-100 chip manages 2 sub-samples and thus writes to two T-Buffers. The writing is done to the invisible "back "T-Buffer, which is similar to the front-and back-buffers normally found on 3D accelerators. The front buffer is written to the monitor while rendering is done in the invisible back buffer. This avoids artifacts like tearing.
4. Once all the geometry for this frame is jittered and rendered to the T-Buffers, we end up with each T-Buffer containing the pixel-colors for each jittered scene. Each buffer contains a sub-sample of the final image, as illustrated in Figure 5.We now flip back and front T-Buffers.

5.The front T-Buffers now contains the sub-samples of the scene we just rendered. The sub-samples now need to be combined to form the final anti-aliased image. This combining is done just before the RAMDAC by special video circuitry that mixes the various buffers together at the pixel level. The RAMDAC is a special component of a 2D/3D chip that translates the contents of the buffers into a signal that can be displayed by your monitor. Most monitors take analog signals as input, which explains the DAC part of the name: Digital to Analogue Converter. The RAM refers to the fact that the AD conversion is done using a table contained in RAM (this has to do with Gamma Correction).The main advantage of this approach is that no down-sampled version of the image has to be stored and the color depth at the output level is higher than the color depth of an individual buffer. The sub-sample T-Buffers can contain, for example,16-bit color, but the combining operation (mixing of the colors) is done at a higher accuracy by the video circuitry which leads to a final anti-aliased image with a color depth higher than the color depth of the individual buffers. This principle is similar to that of the post-filter technology found in the Voodoo2 and 3 designs [3].
A schematic overview of this technique can be seen in Figure 6,below.
This same technique can also be implemented in hardware that supports an Accumulation Buffer [2][4]. However, the traditional Accumulation Buffer technique has some disadvantages in implementing RGSS. The jittering has to be done using software and the geometry thus has to be sent several times to the hardware. The T-Buffer capability of the VSA-100 does this jittering at the hardware level, internally saving valuable bandwidth (the geometry data only needs to be sent once to the VSA-100, as the chip itself automatically jitters the geometry and renders into the T-Buffers). Traditional hardware T&L accelerators can calculate and apply the shift in hardware, but the geometry still has to be sent to the rendering core several times. Another disadvantage of the Accumulation Buffer lies in the recombining of the samples. T-Buffer does this just before the RAMDAC level while traditional systems require a costly copy and combine operation that merges the Accumulation Buffer contents with the frame-buffer contents after every sub-sample is calculated. More details about the Accumulation Buffer technique can be found in [2] and [7].
Note that the Linear Frame Buffer issue raised in the above section describing the OGSS implementation is not a problem for the VSA-100.This is because all of the T-Buffers have the same resolution as the final image. Instead of writing to just one buffer, the VSA-100 hardware writes the data to all T-Buffers automatically. Furthermore, for Linear Frame Buffer reads, the VSA-100 architecture merges the sub-samples together to form the anti-aliased pixel result before the data is returned to the CPU. This allows screen captures done by the host CPU to look identical to what the user sees on his monitor. These techniques allow the VSA-100 to implement RGSS anti-aliasing in a manner completely compatible with all 3D APIs.
Also note that OGSS can also be implemented on the VSA-100 architecture as the sub-sample position off-sets are actually completely programmable by software. Implementing OGSS on the VSA-100 would simply entail using different sub-sample positions (in the case of OGSS, a regular ordered grid).
Summary
We've thus discussed the different implementations of super-sampling, focusing on Ordered Grid Super-Sampling and Rotated Grid Super-Sampling. The primary difference identified between the two methods is the location of the sub-samples within the anti-aliased pixel. We also discussed the implementations of these methods using PC 3D accelerators. The next part of this white paper will discuss the difference in image quality between the two super-sampling two methods, as well as several other key points.