One of the most asked questions I get is : Why does PowerVR use Infinite Planes?
And until not so long ago I was unable to answer this question correctly. However the discovery of the Patent concerning PowerVR has helped me to solve the question.

Now all you need for the visibility are the distances from the start for each plane. The calculations are done by pushing every polygon (define by Infinite Planes) in the scene through some algorithm and the result is a depth value along the ray. This is done for each polygon and in the end you can just look at all the depth values along the ray to know what polygon determines the color for that pixel that the ray belongs to :

So what about transparency?
Well if a the first intersection is with polygon that is transparent that the system will know look for the first polygon (closest to the observer) that is not transparent, while searching all transparent surfaces are also stored somewhere in a buffer in the correct order. The first solid polygon will determine the base color of the pixel, the transparent polygons can then be added render pass per pass by reading from the buffer. Notice how the transparency is automatically per pixel in the correct order no pre-sorting is thus required.
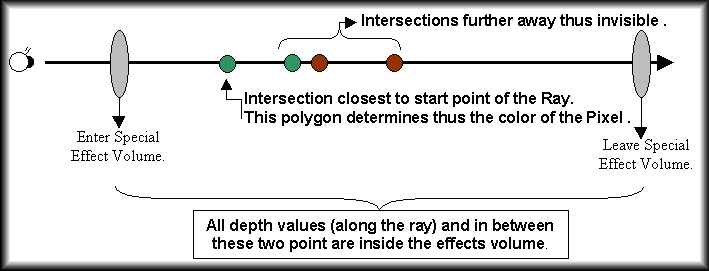
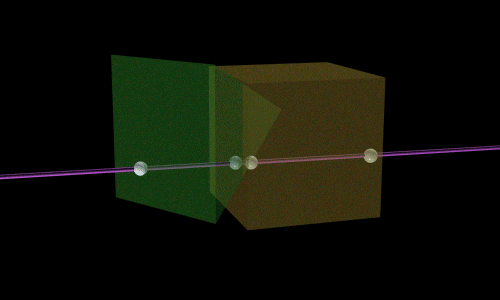
And the special effect volumes?
Well special effect volumes are handled slightly different. The ray will intersect each volume twice : once to enter and once to leave it and both depth values along the ray are stored. When the visible pixel (closest to the observer) has been determined its depth value along the ray will be compared with the enter and leave volumes of the special effect volume. If the depth value of the visible pixel is between the enter and leave value of the special effects volume that an flag is set that tells the system that the pixel is in the volume, in the other cases the flag is not set since then the visible pixel is not an element of the volume. Using this flag the renderer can decided how to render the pixel correct : for example use a different texture if the pixel is in the volume. These effect volumes are for free and do not use up extra fill rate, traditional systems have to use multi pass rendering to simulate these effects using a stencil buffer and that consumes valuable fill rate.
Following figure shows a special effect volume :