In summary, motion blur is created by the fact that the object moves very fast in a specific direction. While moving, the object passes through an almost infinite number of different positions. We see all of those positions because our eyes combine and blur all the different positions together. To approximate this effect using 3D rendering hardware, we can place copies of the object, possibly morphed, at various intermediate positions and we combine the results of rendering those multiple positions in a single motion-blurred frame.
To approximate focus (Depth of Field), which is again a type of blur, we can jitter objects and combine the various jittered positions. By jittering I mean a displacement in space. We could, for example, position an object more to the left, right, up, or down of the original position for each respective buffer. The buffers, thus, contain shifted versions of the original object. If we combine those shifted versions we get a blurred out of focus version of the object. By shifting more or less in those 4 directions we can create a more or less out of focus effect.
Anti-aliasing can be seen as a special case of the jittering used for Depth of Field. Anti-aliasing is a technique to avoid the staircase effects at the edges of polygons and the Moiré patterns inside polygons. Both these problems appear because the number of pixels on the screen isn't high enough to avoid them. For example, the jaggies at the edges appear because the edge can only jump from pixel to pixel, there are no intermediate pixels available. Moiré patterns are similar, but are caused by the fact that the texture cannot be reproduced correctly with the number of pixel on the screen. A very simplistic example is this: assume we have a texture that has black and yellow strips interleaved. Now, that texture has a resolution of 128x128 pixels. Let's assume that this texture is applied to a polygon that is 64x64 pixels on the screen. Now, due to the fact that we have 64x64 pixels on the screen to show a 128x128 texture we need to select texels (pixels in the texture) to show on-screen. Now, with some bad luck this can result in only yellow pixels being selected (sampled -assuming point sampling), this is, of course, not a good representation of the texture but an unfortunately result of sampling (=selecting texels from the texture map to determine the color of on-screen pixels). With increasing polygon sizes this effect gets even worse: the lines will start to move around depending on the size of the onscreen polygon.
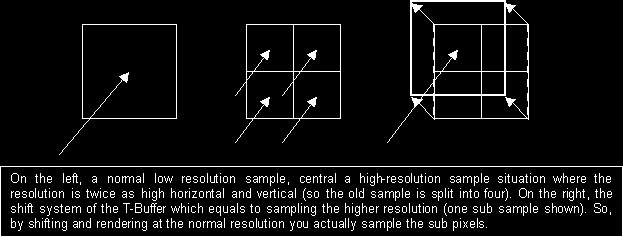
Now, how can we avoid this? We can avoid this by taking more samples per pixel. Usually this is achieved by rendering at a higher resolution and down-sampling. If you render a scene at 1600x1200 and you then take pixels together in-groups of four you can achieve anti-aliasing. The T-Buffer can be used to achieve the same effect. Instead of rendering the scene normally we jitter the scene at a sub pixel level. By moving all objects up, down, left, or right for the respective buffers over a distance of half a screen sub-pixel we can achieve the same effect as rendering at a higher resolution. You can see it like this:
Assume the 3D world is a box, a box with one transparent side. This transparent side is your monitor. Now, when you look at your monitor you actually look into the box that contains the 3D scene. Now, your screen has a certain resolution, meaning that you have a specific number of pixels in both the horizontal and vertical direction. You can see these pixels as small rectangles. The color of each pixel is determined from the 3D scene inside the box. You can see it like this: you shoot a ray through the center of the pixel into the 3D scene. This ray will intersect with the side of a certain object. This object has a certain texture, now using a lot of mathematics you can figure out which position inside a texture (2D picture) determines the color of that pixel (with bilinear and trilinear filtering you use more than one pixel from that 2D map). Now, if we jitter the scene at the sub pixel level we kind of move the point where the ray ends. For each buffer (scene is jittered) we move the ray point towards the center of the 4 sub pixels. This means that samples will be taken at a sub pixel resolution. By combing the 4 buffers we can thus down-sample the higher resolution. The picture below illustrates these sub pixel positions: