Tesla Adoption & Deployment
The HPC industry is quite conservative, and therefore you shouldn’t expect everyone to adopt such a fundamentally new paradigm overnight. For example, x86 clusters took many years to get where they are today despite already becoming attractive in the late 90s:

There are two aspects to this. First of all, it takes time for software to be ported (and for people to realize it’s worth the effort to port it); this is even more true for GPUs than for x86, because you’re asking the developer to fundamentally change his way of thinking. Secondly, the deployment schedules can be very long in certain industries for a variety of reasons. For example, certain medical diagnosis methods made more viable through this higher level of performance may still take a long time to get approved by the FDA.
The argument NVIDIA likes to make on this subject is that unlike practically all past transitions, both successful and failed ones, this one delivers truly massive improvements in raw performance, performance per dollar, performance per watt and performance per square meter. They’ve obviously run many models to quantify that advantage, and have come up with the following numbers when comparing CPUs and GPUs to achieve a 100TFlop supercomputer:
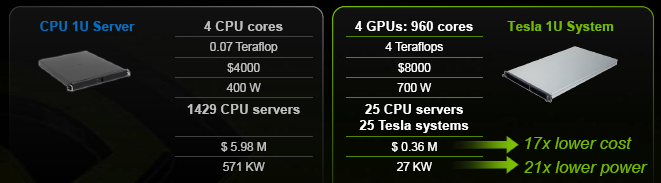
UPDATE: It was nicely pointed out to us that this comparison isn't really fair in fact, and should be reduced by a factor of ~2x: for $4000 and with a 400W typical power consumption, a 1U server with a dual-socket motherboard and two quad-cores would be a much more realistic configuration for a cluster in the HPC world. Yes, there are 1S systems for that price, but their target market is different and they would also often (for example) include a substantial amount of HDD storage that would not exist on the Teslas. Of course, ~10x lower cost/power while taking ~14x less space remains very impressive, so this is far from being a deal breaker.
On the other hand, it's worth remembering this advantage would become much much smaller with double precision, since CPUs are half-speed and Tesla is 1/8th speed; this further highlights how DP isn't for cluster deployment this generation, but for prototyping/development/research. Also, 0.14 Teraflops matches what you would expect from a 2S 2.2GHz Barcelona; clearly that's not the highest-performance CPU in the world, but it's also far from fundamentally unfair.
For DP, however, it's clear that NVIDIA has more intense competition: There's RV770 obviously, and more importantly there's ClearSpeed out there with a 1U solution that delivers slightly lower cost and much, much lower power/space requirements. Clearly for large-scale applications that warrant large cluster deployments and custom software development (and aren't too limited by bandwidth), ClearSpeed feels very attractive this generation.
For individual researchers, NVIDIA (or ATI) would seem much more realistic, let alone because you can use a vanilla GeForce or Radeon for application development instead of buying a much more expensive HPC-oriented card immediatly (or at all, as we'll ask to Andy in a second). It will be very interesting to watch how the relative cost/power/space equation evolves in the coming years and generations, though.
---
Anyway, it’s certainly much harder to resist porting code to a new architecture when the cost benefit is 95% than when it’s ‘only’ 50%. That’s the difference between needing $1M for a large project or just $50K; if management asks you to justify the expenditure compared to the alternatives, it’s going to be a lot harder to do so with a straight face than if you just ‘maybe could do it at $500K with a lot of effort and additional risk’. That's why GPGPU has the otential to really achieve momentum throughout the industry.
We wanted to know a bit more about NVIDIA’s expectations for revenue and customer deployment schedule, as well as a couple of other miscellaneous tidbits, so we poked Andy Keane (General Manager of the GPU Computing) over dinner on Editor’s Day and had a quick ten minutes chat with him. We apologize if we had to paraphrase some of the questions and answers, but the room was so noisy that we already took more than two hours just to get this transcript together – so bear with us, and enjoy!