Command Processor, Thread Setup and Setup Engine
Command Process and Thread Setup

The command processor and thread setup are what get the chip doing useful work, accepting a command stream and data from the driver, which in turn is working on data provided to it by the graphics API asking the hardware to do something. The command processor in R600 is also responsible for validating hardware state asked for by the application, to make sure it's configured properly for any given set of ops needed to be executed. Previously the driver was entirely responsible for state checking, but D3D10 compliance mandates the hardware do at least some of the job to reduce CPU overhead when drawing. Combined with runtime overhead reduction in D3D10 as a whole and the simple task of asking the GPU to do some work consumes less host cycles than before.
The command processor is able to snoop the state of the processing units on the chip, so that it doesn't set state needlessly when it's already configured the right way, or when it simply doesn't need to be set because the state being asked for is invalid. State validation on R600 is also applied to D3D9 apps on Vista or XP/2000, so they see some benefit too, the driver not implementing old state management routines needlessly when there's logic on the chip to accelerate that. Alongside state validation and setting, the command stream is processed by thread setup logic, which determines thread type and batches ops and data to be passed further down the chip.
Setup Engine
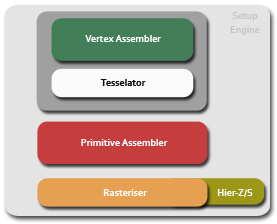
We split off thread setup as coming before the Setup Engine, but we could just as easily have grouped it in there. It's responsible for getting thread ops and data into the right shapes and formats for the shader core to chew on, before passing down a thread batch for the dispatch hardware to execute. You'll see that part of the chip later in the article. When it comes to vertex processing, the setup hardware is responsible for arranging data in card memory for optimal access, so that vertex fetch isn't memory bound. It's also responsible for configuring and feeding the tesselator.
The tesselator is pretty much the same programmable unit in the Xenos processor in Xbox 360, which allows the developer to take a simple poly mesh and subdivide it based on a surface evaluation function. That function helps setup the maximum tesselation factor, how the subdivision rules should be applied to the mesh (to support different subdivision surfaces), and how recursion should work for tesselating geometry created by the tesselator. As part of setup it's in the pre-shading stage and outputs geometry and texture coordinates for the geometry assembler to work on. We could write an entire article on the tesselator, how it works, how you program it inside of D3D even though it's not part of the API. Indeed we will, so apologies the details are somewhat light in this piece.
Tesselation is free in the sense that generated geometry almost never hits board memory, but that can happen and there's a cap on subdivision, and you can also be limited by the rasteriser we imagine, given certain input geometry and the evaluation function. More on that in the dedicated tesselator piece. Rasterisation generates fragment tiles from geometry, for the shader core to chew on, working to what we think is the same 16x16 screen tile method as the previous generation of Radeon hardware.
As part of improvements to setup, R600 implements tweaked hierarchical-Z, tuned for very high pixel counts where performance is maintained even for 4Mpixel or higher displays, and also hierarchical stencil. The hier-Z/S buffers represent different coarse grained looks at the depth and/or stencil values in a tile, to determine whether to throw away geometry before rasterisation, pre-shading, to limit the number of pixels sent through the hardware. Of course, early-Z in the traditional sense (testing and rejecting every pixel individually) also occurs, but hier-Z helps reduces the number of tests that have to be done as more pixels can be rejected in one go, and it also saves bandwidth. Each stage in the buffer pyramid contains a different number of discrete values for Z/S, which the hardware checks to decide whether or not to throw the tile away or send it down.
The setup engine also performs attribute interpolation according to the presented slides, to setup those for shading, although we have that logic shown in the shader core in our diagram. With setup complete, the engine dispatches ready threads, which can be variable size in terms of objects, to the shader core for further processing. The hardware can fetch 16 vertices per clock out of card memory, setup one complete triangle per clock (for a peak rate of 742Mtris/sec on HD 2900 XT)
The threading model is arguably one of the most important facets of AMD's latest graphics architecture, so we'll spend good time talking about that.