'Accuview' Antialiasing
Primarily, Accuview is a refinement on GeForce3's Multisample antialising.
One of the first differences between Accuview's Antialiasing and that found on GeForce3 are the slightly altered sample locations for 2x and Qunincunx modes.
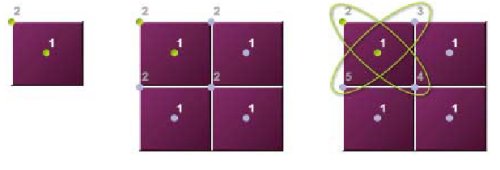

Because multisampling only takes one texture sample for all the subsamples, under GeForce3's 2x & Qunincunx schemes the texture sample would be exactly suitable for sample point 1 (being in the centre of the sample) but not very suitable for sample point 2 (as this is at the very edge of the pixel, bordering the next). By shifting both the subsample positions such that each are roughly equidistant from the pixel centre, both samples contain a small level of texture error rather than one containing none, and another containing lots.
nVIDIA have also introduced a new 4X Antialiasing mode called 4XS. This mode introduces a subpixel coverage that is 50% greater than its predecessor, and also samples more textures.
Accuview also features pipeline improvements for greater Antialiasing processing speed. One of the main issues of Antialiasing, even Multisample AA, is that of bandwidth; for 4x FSAA the back buffer has to be four times the size of the final image and when the image is finally drawn this large backbuffer needs to be read back into the chip to perform the subpixel averaging and then write back out to a front buffer which is the actual size of the display resolution. Accuview reduces this overhead by removing steps of this process and doing them in parallel.
Lightspeed Memory Architecture II
The first element of the memory architecture is the 'Crossbar' memory controller. This appears unchanged from GeForce 3 with four 32bit DDR memory banks each being able to address memory rather than a single 128bit bus..
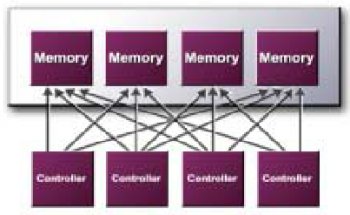
The principle behind the crossbar is not about achieving greater theoretical bandwidth, but improving efficiency to better utilise the available bandwidth so that the actual bandwidth used comes closer to reaching the theoretical peak. If we take the example of a single 128bit DDR bus needing to access four 64bit chunks of data, because it is a single bus these have to be queued, thus for each of the 4 chunks received only a quarter of the available bandwidth is used; in the case of GeForce4's memory controller each of the 4 banks can access this data simultaneously, hence all four chunks can be retrieved in only one attempt rather than 4. Should a full 256bit chunk of data need be accessed then all the controllers operate together to retrieve the necessary information.
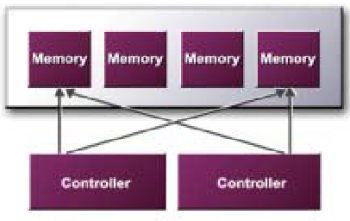
This time, the GeForce 4 MX's also benefit from a crossbar memory controller. However, probably due to MX's pipeline configuration, the chip features two 64bit (DDR or SDR) controllers rather than the 4 found on the GeForce4 Ti.
Also familiar from GeForce3 is its Z-Occlusion Culling system. This system has two features, the first being a simple overdraw removal scheme and the second being an Occlusion Query. Z-Occlusion queries the pixels location prior to rendering and if it determines that it would be rendered behind an opaque object then no further operations will be carried out on that pixel, and hence there will be no further framebuffer access for it; nVIDIA states that this method can achieve up to 4 times the performance indicating that 4 pixels per pipe can be checked simultaneously. Occlusion Query requires developer support to take advantage of it; Occlusion Query works by putting a basic 'bounding box' around an object, such as a character model for instance, and rather than every vertex in the model being tested for visibility, just the points of the bounding box is tested - if the entire thing is deemed to be occluded then the entire model can be removed and not rendered at all.
Lossless Z-Compression, also featured on GeForce3, makes a return here. Z compression can compress Z values up to a compression ratio of 4:1, which in a best case scenario reduces Z buffer bandwidth used by a factor of 4.
Similarly Fast Z-Clear also makes a comeback. Fast Z-Clear flushes the Z buffer of old data much faster than previous systems which results in a minimised bandwidth usage.
nVIDIA also features what they are calling 'Quad Cache'. Basically the caches in GeForce4 are split into their individual tasks: one each for primitive, vertex, texture and pixel data caches, configured optimally for the task they are designed to do.
Also featured for GeForce4 is memory Auto Pre-Charge. DRAM is organised in rows, columns and banks, however this configuration only allows immediate access to the current row and column of an active bank. If data needs to be written/read from another area of the chip the current bank must be closed and a new bank opened with the row and column coordinates of the memory address required, however the new bank being activated must first be 'pre-charged'; this pre-charge process can cost up to as much as 10 clock cycles. Auto Pre-Charge will 'proactively' pre-charge a memory bank so that when it actually needs to activate the areas on that bank it will not have to wait for the pre-charge process. All that it has to wait for now is the activation step which, dependant on memory vendor, can be as little as 2 or 3 clocks.