Rendering Pipelines
Here we'll take a closer look at the pixel rendering pipeline organisation of the R420.
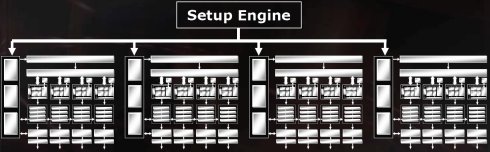
The diagram above shows each of the rendering pipelines as they are organised in quads, with 4 quad pipelines giving a total of 16 pixel rendering pipelines. As mentioned, each quad can be turned off in the hardware and the rest of the quads will still transparently operate, which means that the chip is not only capable of a 16x1 rendering operation, but 12x1, 8x1 or even 4x1.
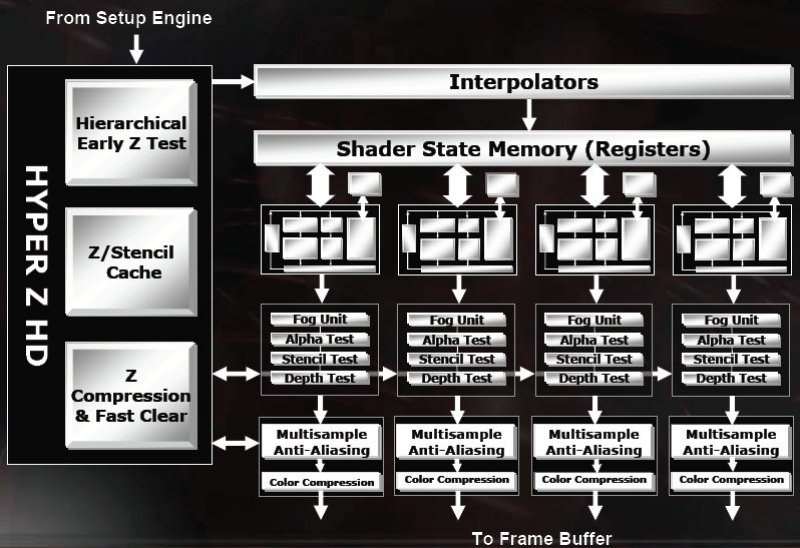
ooking at a single quad pipeline you can see that the Hyper-Z functions, including the Hierarchical Z-Buffer, work at a per quad basis. This means that the Hierarchical Z-buffer is scalable to the number of pipelines. With the Radeon 9500 ATI had to turn off the Hierarchical Z-Buffer entirely from the pipeline, which meant that it was always relying only on the early pixel level Z reject, which requires some memory bandwidth and can also stall to a greater degree than the Hierarchical Z-Buffer, however with R420 this is not the case and each quad pipelines Hierarchical Z-Buffer will still be enabled.
With 4 quads enabled the Hierarchical Z-Buffer has around 4 mega pixels of (lower level) Z buffer storage capabilities, which should be good for over 2048 resolutions, which means that high definition resolutions like 1920x1080 are fully covered. Should the screen resolution exceed that of the maximum capabilities of the Hierarchical Z-Buffer it is not disabled entirely, instead a portion of the Z-buffer is setup in the Hierarchical Z-Buffer to its maximum storage capability and then anything that falls out of that range falls back to the early pixel level reject, so the majority of the screen can still be captured by the Hierarchical Z-Buffer.
In full, 4 quad operation, the Hierarchical Z-Buffer has the maximum capability of rejecting up to 256 occluded pixels per cycle. The Hierarchical Z-Buffer can also do two Z or Stencil compares per pixel, per cycle as well, potentially speeding up the Z/Stencil rendering performance.
Each of the quad pipelines also have access to their own Z compression and fast Z clear units. The Z compression operates at a maximum lossless 8:1 compression ratio, which saves on memory bandwidth, and the compression ratio also scales up with the FSAA level in use. Fast Z clear uses a block based Z buffer clearing mechanism that reduces the Z buffer accesses when the Z buffer is cleared between frames meaning fewer cycles are used doing this operation and less bandwidth is used.