The Front-end: Command Processor, Setup

Not the most glamorous of GPU components, the Command Processor is however essential to its well-being, since its task comprises fetching the command stream from registers mapped in host memory, signalling to the host via interrupts and controlling data fetches from host RAM. It's also responsible for state management, retaining the ability to snoop current state of the chip so that it doesn't needlessly set and reset it. For Cypress, and all ATI GPUs starting with the R600, the actual implementation of the CP is done via a custom microcoded unit (RISC-ish), with full memory R/W privileges and multiple command queues. The CP is DMA capable, so it can interact with host RAM without CPU arbitration. We're not sure what tweaks, if any, have been implemented here, outside of an expansion aimed at accommodating DX11 as well as the chip's increased width, and gauging the efficiency of the CP is pretty difficult unless it's utterly bad, in which case one can't help but notice – don't worry, that's definitely not the case here.
After the command stream is decoded into instructions belonging to Cypress' specific ISA, thread setup logic takes them in and batches them into vertex, hull, domain, geometry, pixel or compute threads, whilst also handling data batching and finally passing the results of its work into the setup stage.
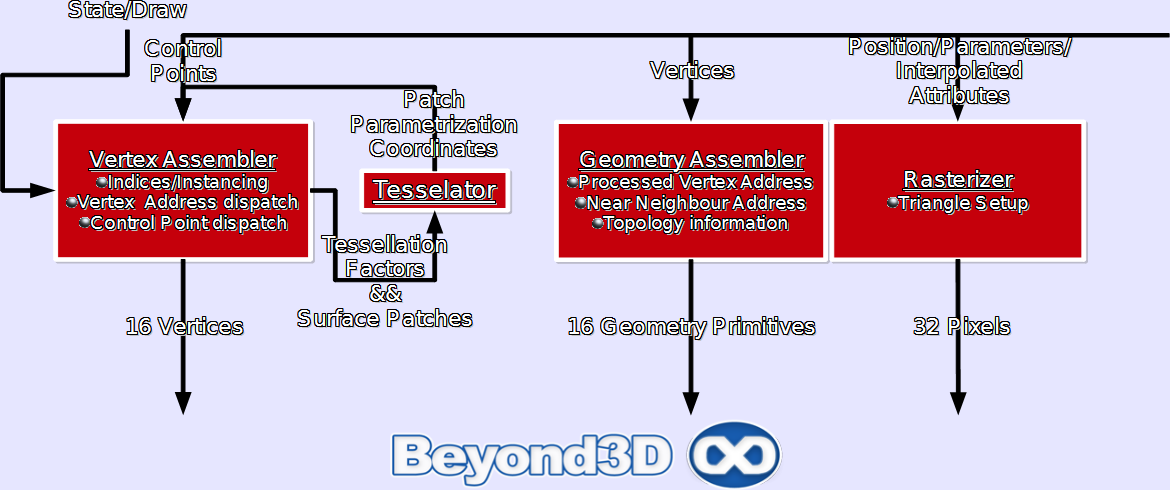
The setup engine is the first element of the chip that has been somewhat significantly modified. We've already touched upon the tessellator achieving “full-citizenship”, but there's more than that happening. But first, let's deal with the elements that have remained constant, namely the vertex and geometry assemblers. The vertex assembler feeds the dispatcher hardware with up to 16 vertex addresses per cycle, whilst also managing how vertex data is arranged in memory in order to avoid bottlenecking vertex fetching, whereas the geometry assembler dispatches up to 16 geometric primitives (processed vertex addresses, near neighbour addresses and topological info).
The tessellator, however, is pretty new, an evolution of hardware that has been with us since Xenos/R600 (we really can't count the 8500's TruForm in this lineage, at least not whilst maintaining a straight face). It's fully DX11 compliant, allowing up to 64X amplification (although for real-time applications that's not exactly a realistic scenario), and supports both continuous and adaptive tessellation. Unlike its forebearers, which were controlled via vertex shaders, in DX11 there are 2 new shader types intended precisely for tessellation, namely Domain and Hull shaders.
The pipeline flow thus: vertex shader->hull shader->tesellator->domain shader->geometry shader->pixel shader (stages are abstracted). Superprimitive meshes can be made up of either triangular of quadratic patches. In fact, there's quite a lot of geekiness hidden within tessellation, and we feel that in the long run it's bound to be one of the big things coming to the 3D world, now that it's officialy supported in DirectX, however, we'd like to keep our eye on the current target, which is Cypress, so we'll avoid being too verbose on the topic. Rest assured, however, that we'll be back with a vengeance once Windows 7 and, by extension, DX11 officially launch.
Getting back to the tessellator, the unit itself is fixed function, rather than programmable, but rather elevated flexibility can be achieved by clever usage of the hull shader.. In our limited time with it, we've put the tessellator through its paces in some of the DX9 tessellation demos that ATI provides, and we've noted that its performance characteristics under those circumstances are eerily similar (read nearly identical) with those that the one in something like the RV790 could achieve, which may hint at the hardware being quite similar indeed. However, that's only one data-point and we'll avoid drawing any sort of conclusion until we've had proper time with it.
One of the possible limiting factors on tessellation was the rasteriser, since one could imagine that beyond a certain amplification factor triangle setup/raster rate would become a bottleneck. To ensure this was not the case, it initially seemed like ATI had chosen a rather simple solution: the addition of another setup and raster unit! This would have allowed them to (theoretically) fetch 32 vertex attributes from memory per cycle and setup 2 full triangles per cycle for a theoretical rate of 1.7GTris/s at the 5870's clock rate of 850Mhz. Practically, things proved to be slightly different: after banging our heads against an ~830 MTris/s rate, which we couldn't surpass irrespective of how simple our triangles were, or how we fed the hardware, we checked back and it appears that triangle setup rate hasn't been bumped up, remaining at the good old 1 triangle/cycle (we can see certain reasons for it). So, in practice, we're dealing with a fatter rasteriser with doubled scan conversion rate, but constant triangle setup rate.
Hierarchical-Z, has been tweaked/expanded, with pixel rejection rate doubling from 128 pixels per cycle to 256 pixels per cycle (we've measured rejection rates within 1-2 pixels of the quoted figures). We initially thought that dedicated interpolators still existed in the setup engine, however after more work with the chip we're quite certain that attribute interpolation is actually performed by the shader core. What's important to take home is that we've had no problems hitting maximum texturing rate, even for very simple texels, something which was not possible with the RV770, which could be interpolator limited under such conditions (only 32 interpolators for 40 Texturing Units). The glorious finale consists of the rasteriser generating up to 8 2x2 pixel quads and sending up as many as 32 pixels per cycle down into the dispatcher.
If the hardware is faced with the friendly scenario of Z-only rendering, the rasteriser can actually generate up to 8 4x4 quads of Z-values, since for Z-only a number of simplifications are possible, with Z/W (thanks Marco!) being nicely linear in screen space and having a constant pixel-to-pixel delta, amongst other things. Fetch constraints are also lowered, since only position and Z are needed for Z-only rendering. What this means practically is that the rasteriser won't turn into a limiting factor, and the only roadblock in the way of attaining the elevated Z-write rates you've seen quoted will be memory bandwidth. Having cleared that up, it's now time to look at the dispatcher.