Analysis: Arithmetic Throughput
Arithmetic tests are simple to write: just do a zillion or twelvety ops, and voila, you have a test. We use the Dynamic Shader Linkage feature introduced in DirectX 11, so as to write the actual work code once, and just bind it in different stages. Note that not all stages are created equal, and that some rely on the presence of others upstream or downstream (a PS needs an active VS, hull and domain shaders exist only in pairs etc.). You'll find the expected rates in the next table, and under it the actually measured rates:
Instruction Issue Rates GTX470
| Single Precision | Double Precision | Integer | |
| Scalar MUL | 544.32 | 68.04 | 272.16 |
| Scalar ADD | 544.32 | 68.04 | 272.16 |
| Scalar MAD | 544.32 | 68.04 | 272.16 |
| Vec4 MUL | 136.08 | 17.01 | 68.04 |
| Vec4 ADD | 136.08 | 17.01 | 68.04 |
| Vec4 MAD | 136.08 | 17.01 | 68.04 |
| DOT2 | 272.16 | * | 136.08 |
| DOT3 | 181.44 | * | 90.72 |
| DOT4 | 136.08 | * | 68.04 |
| Transcendentals | 68.04 | * | * |
Instruction Issue Rates HD5870
| Single Precision | Double Precision | Integer | |
| Scalar MUL | 272 | 272 | 272 |
| Scalar ADD | 272 | 272 | 272 |
| Scalar MAD | 272 | 272 | 136 |
| Vec4 MUL | 272 | 68 | 68 |
| Vec4 ADD | 272 | 136 | 272 |
| Vec4 MAD | 272 | 68 | 68 |
| DOT2 | 544 | * | 136 |
| DOT3 | 272 | * | 90.6 |
| DOT4 | 272 | * | 68 |
| Transcendentals | 272 | * | * |
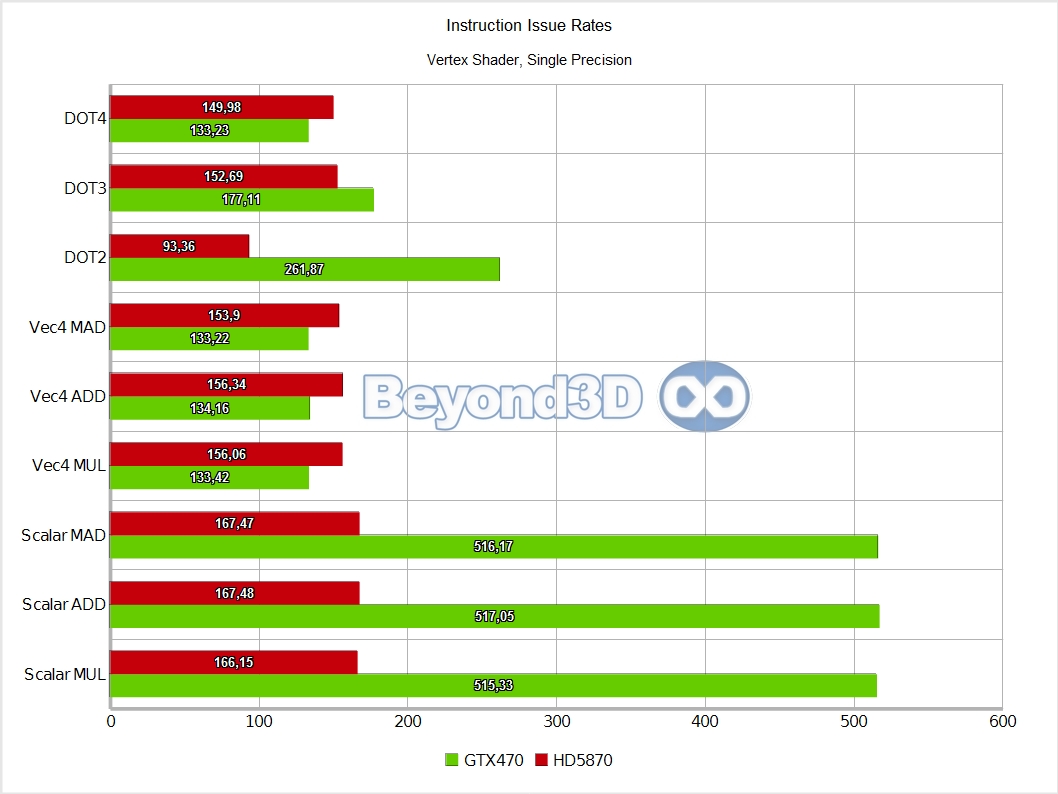
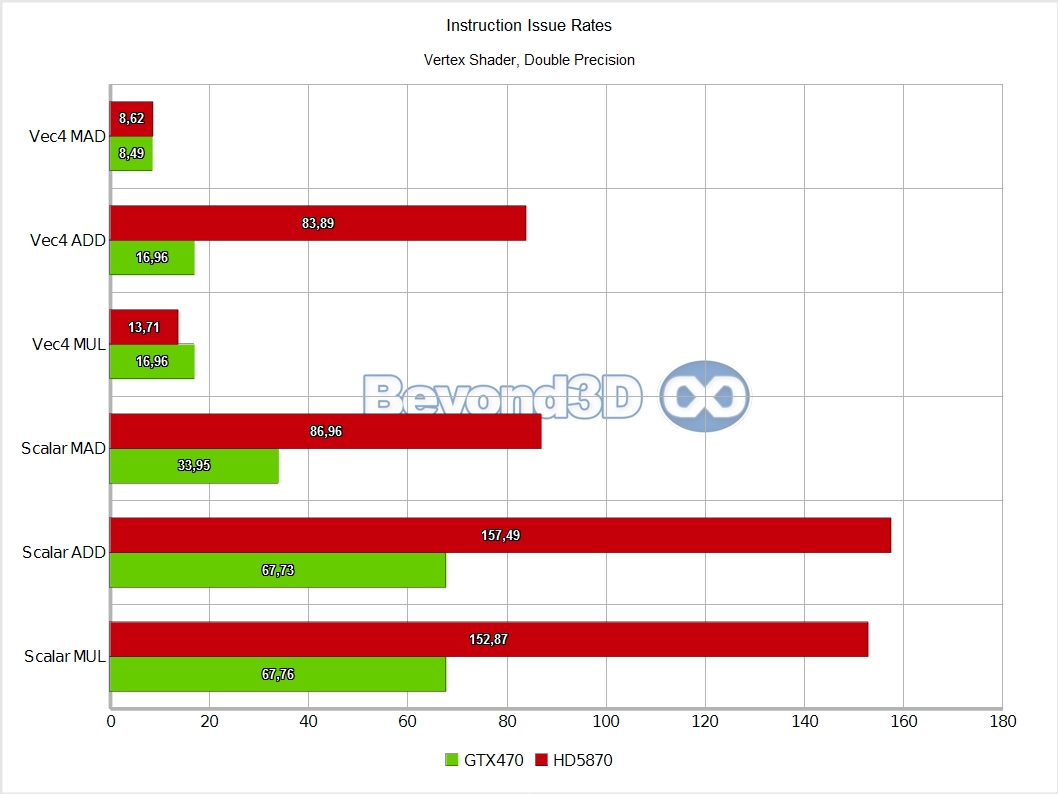
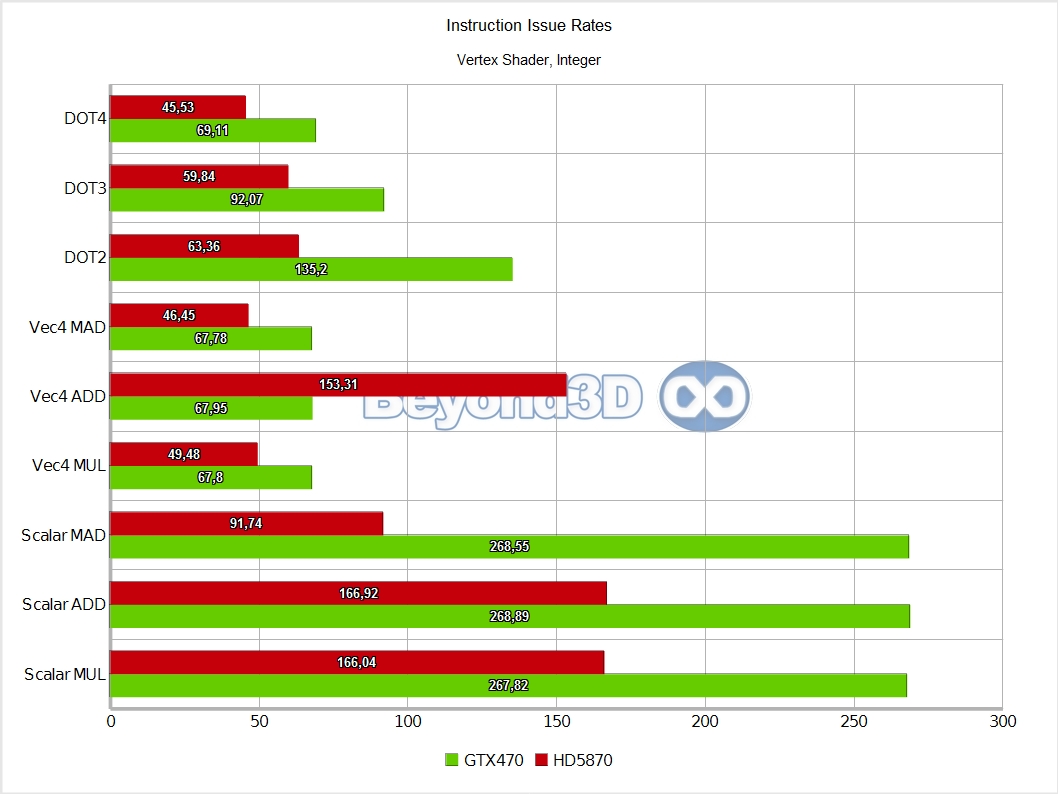
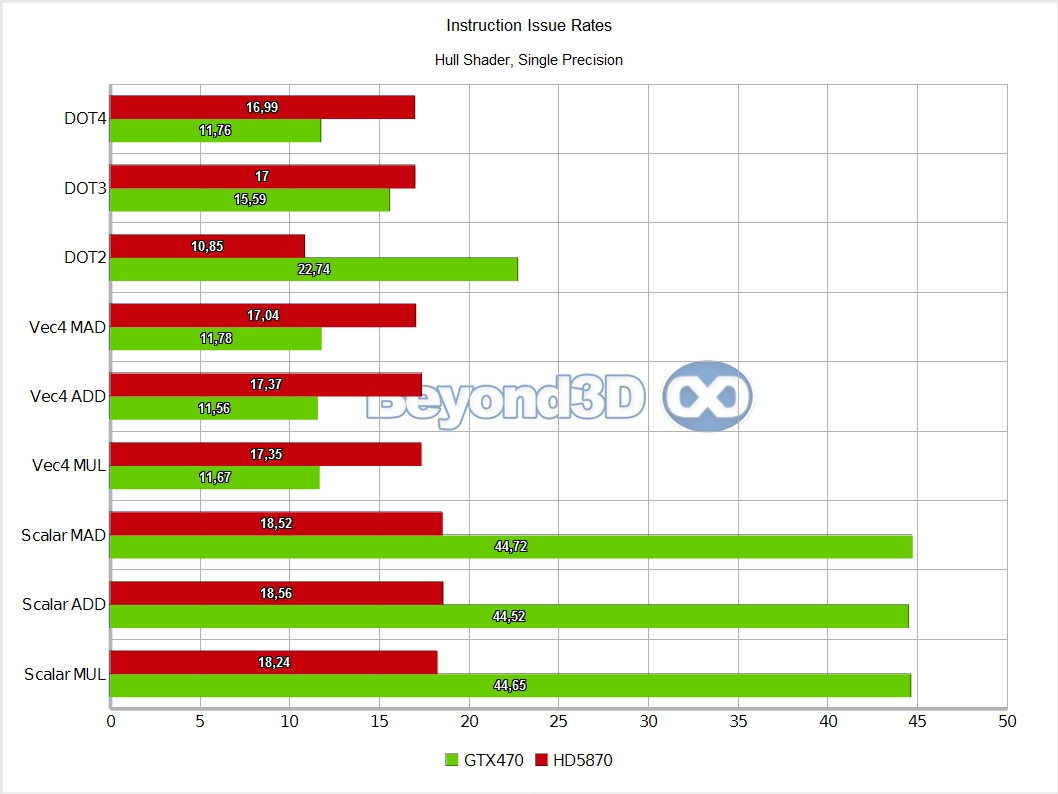
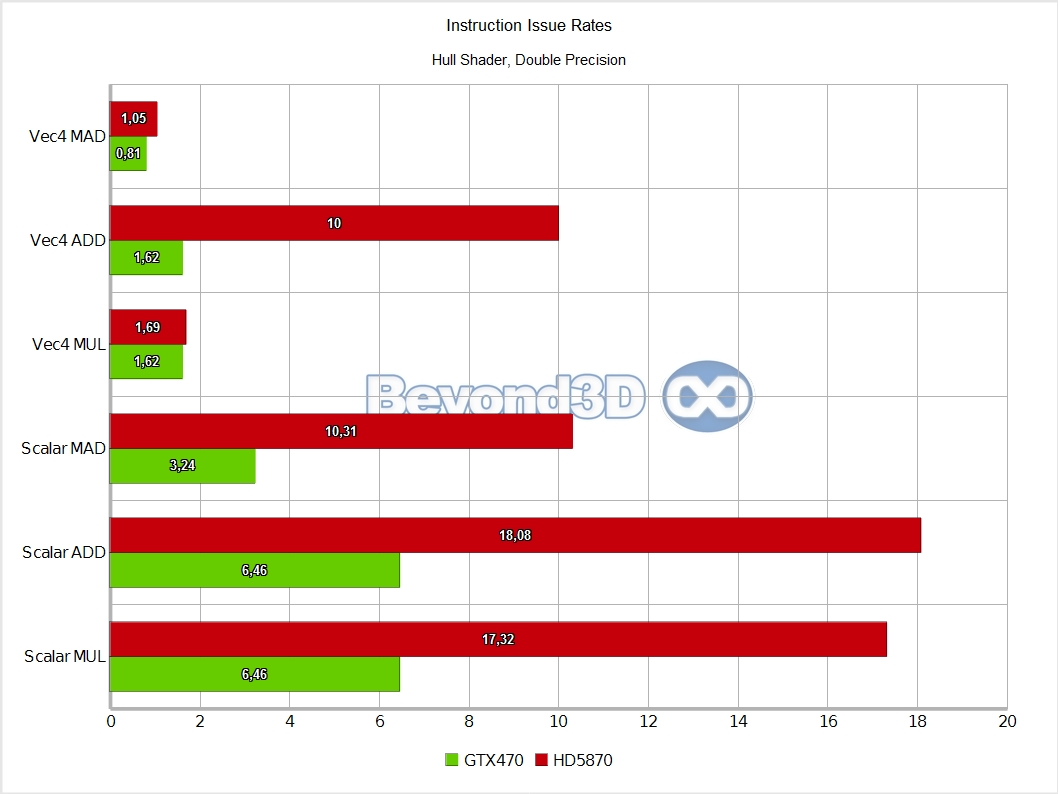
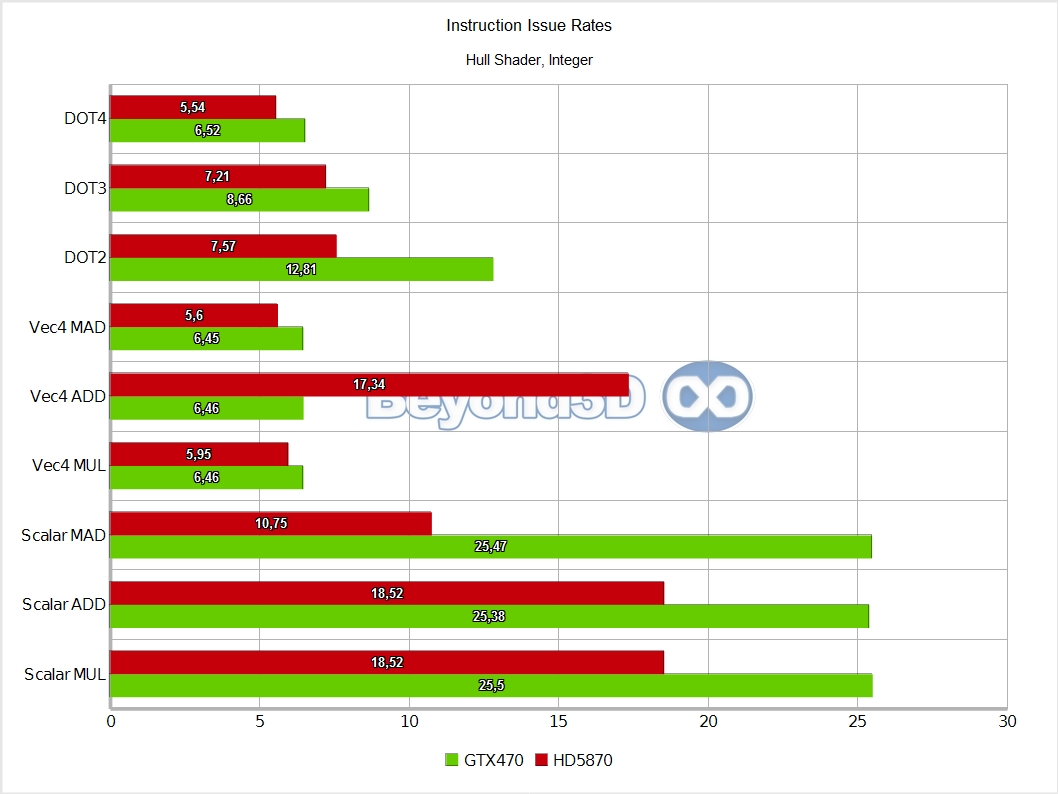
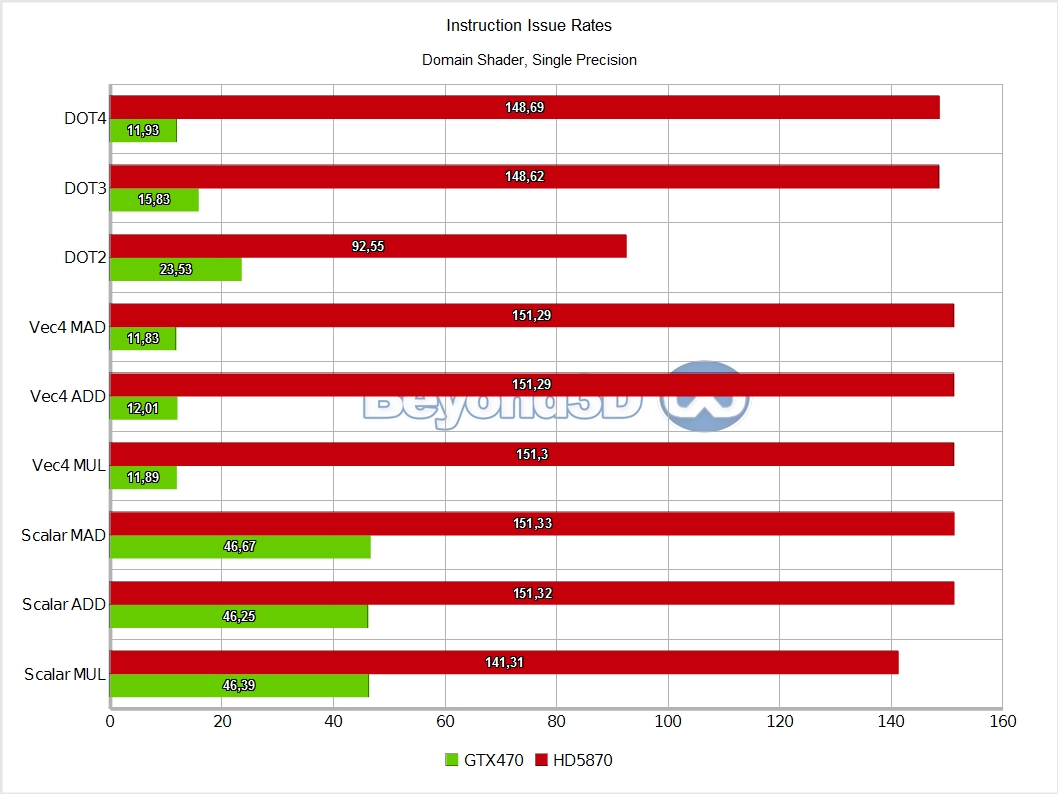
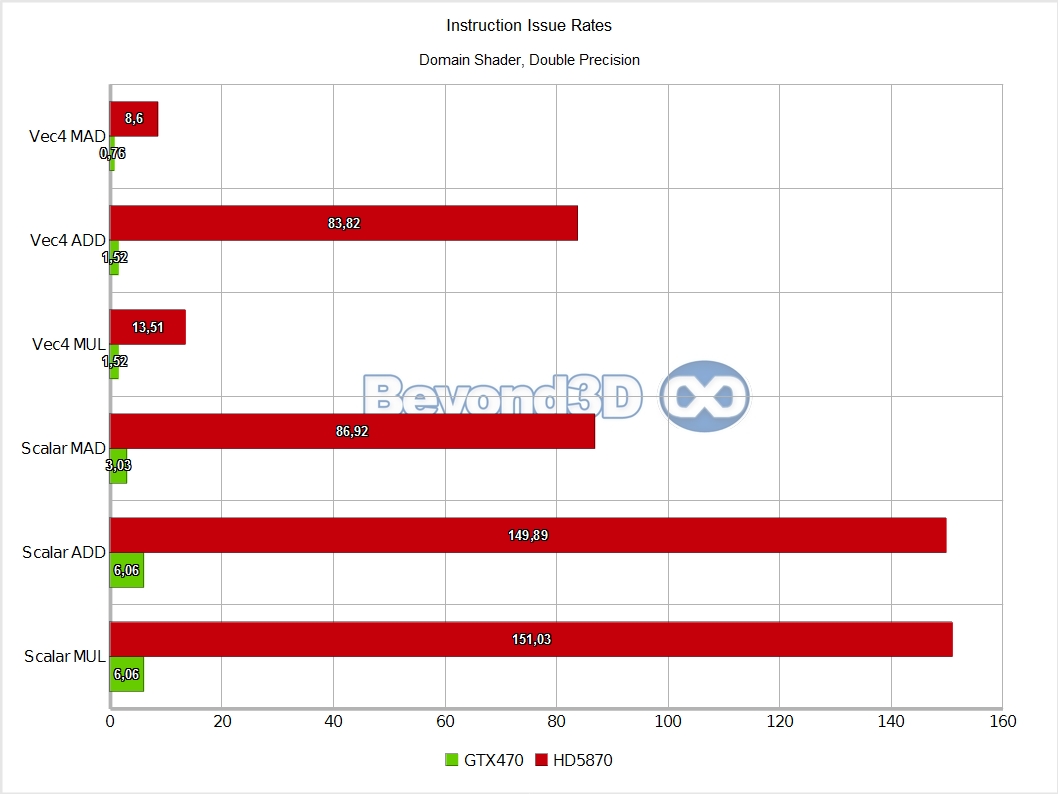
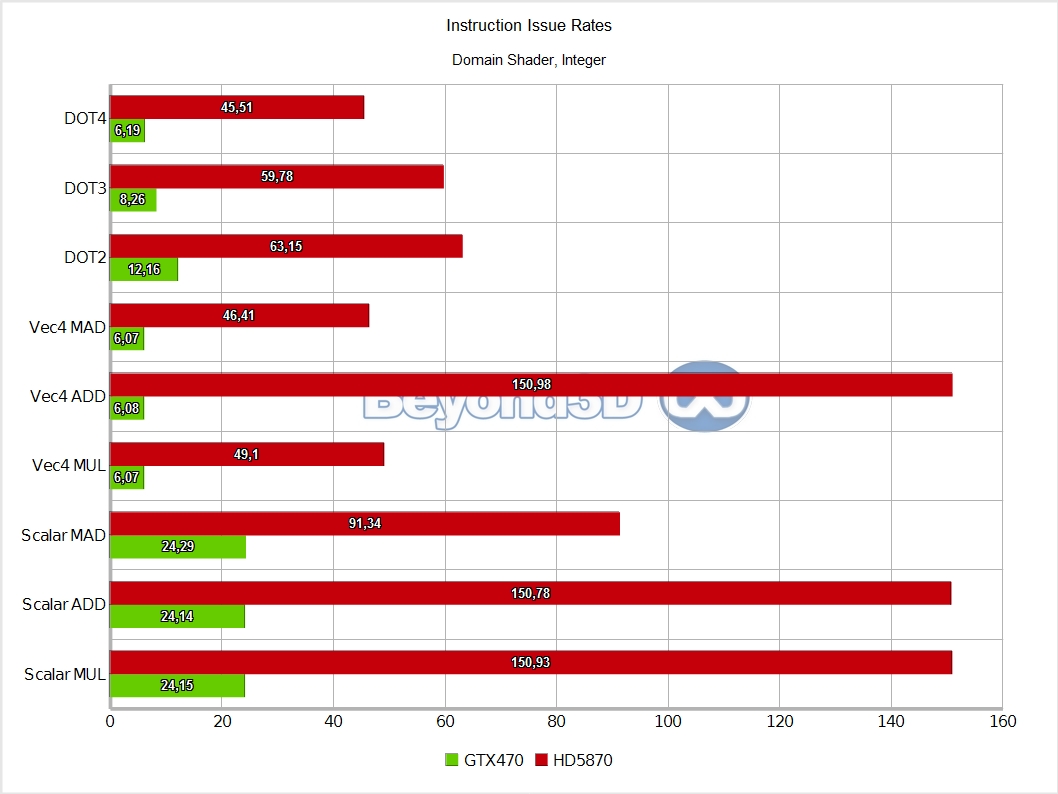
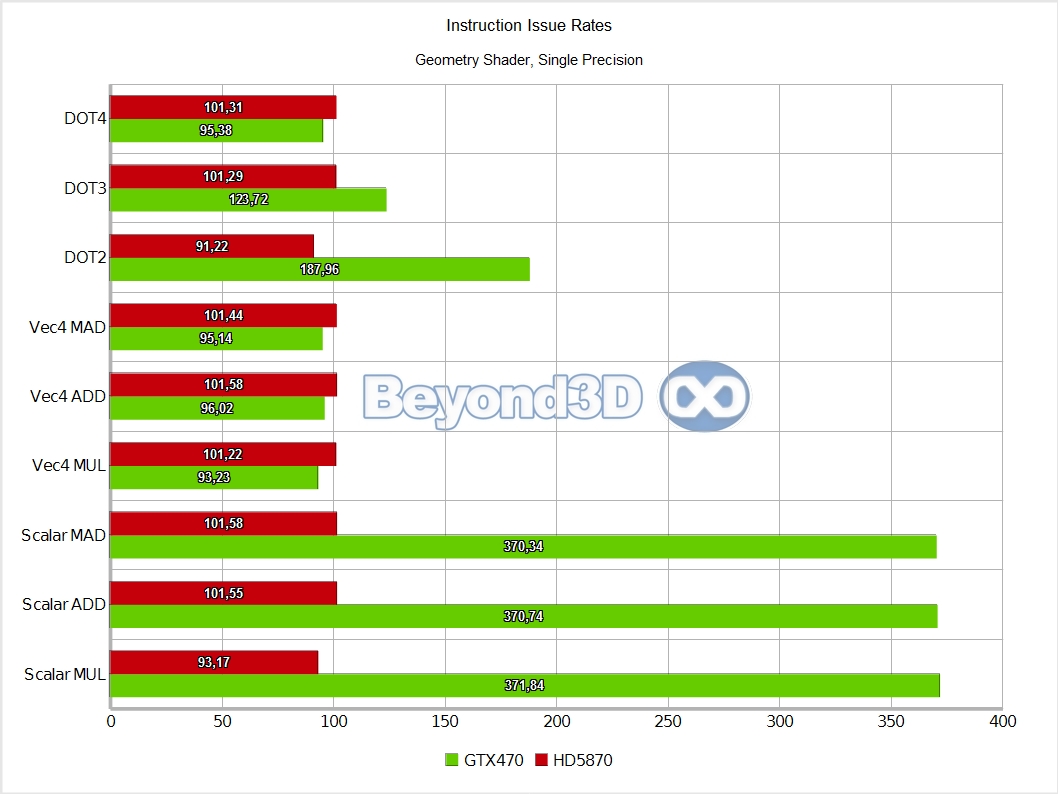
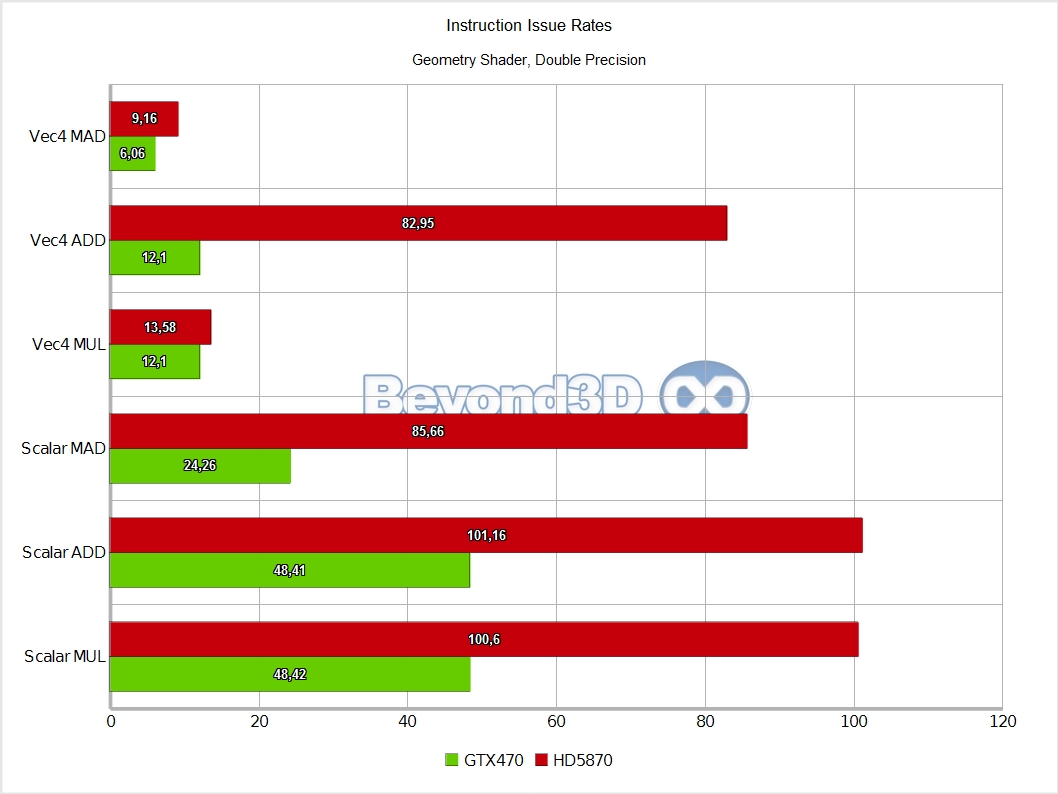
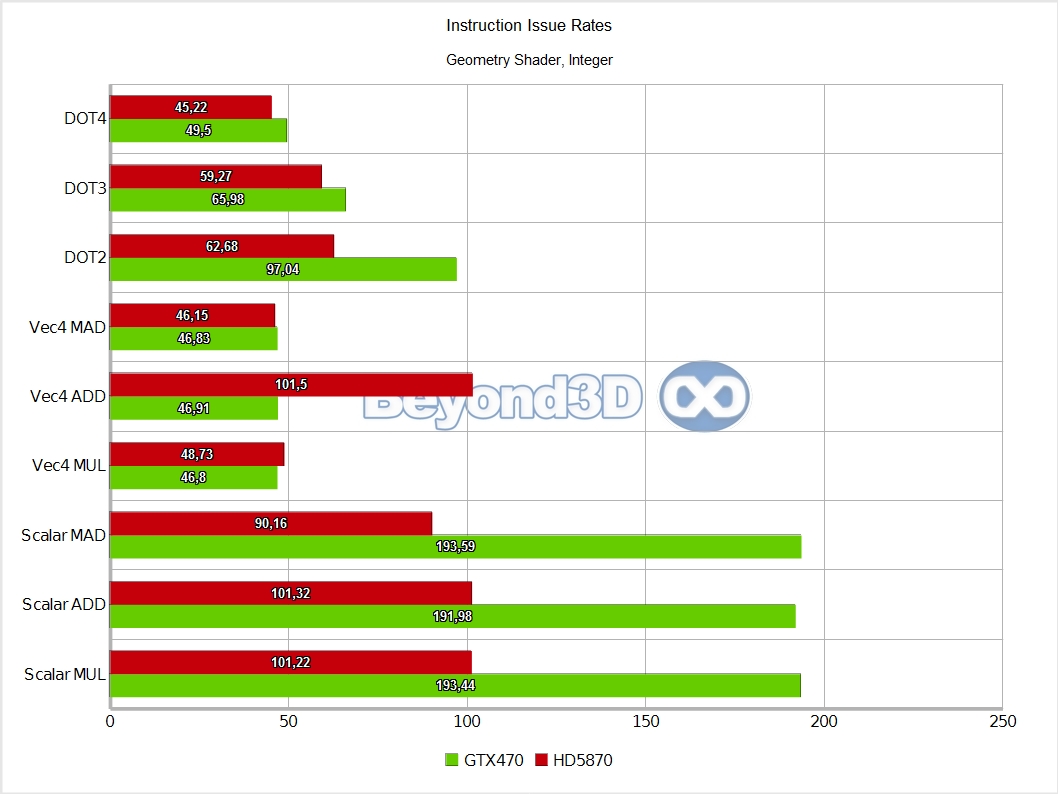
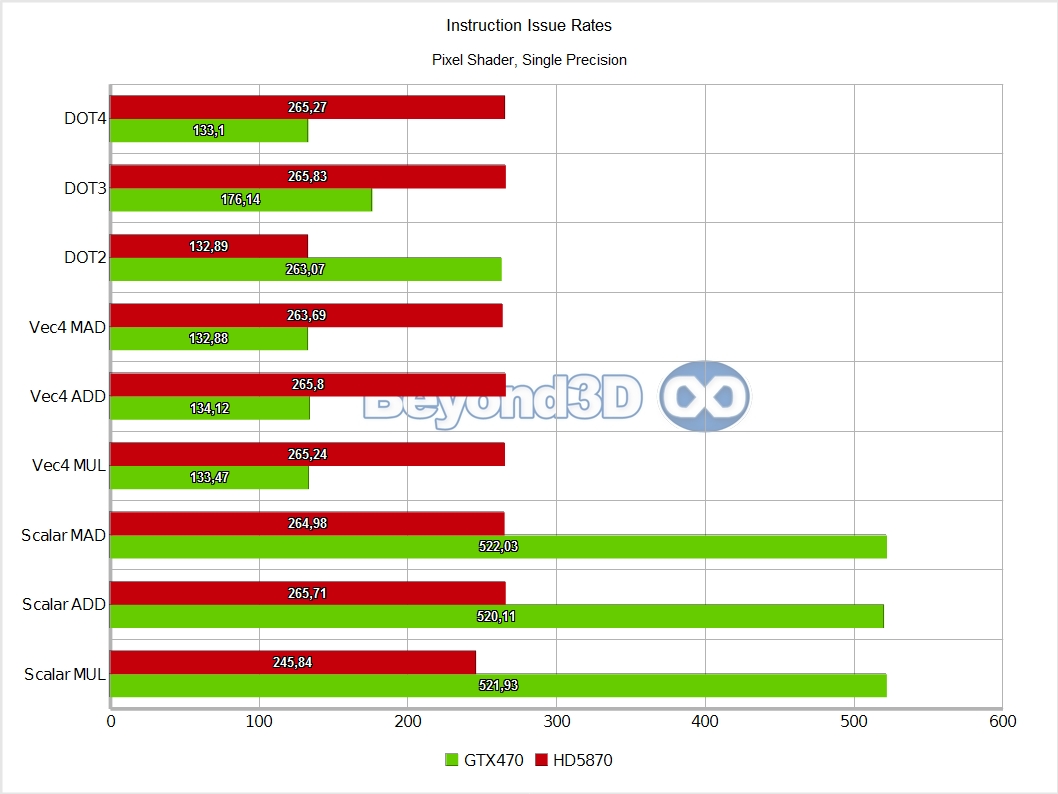
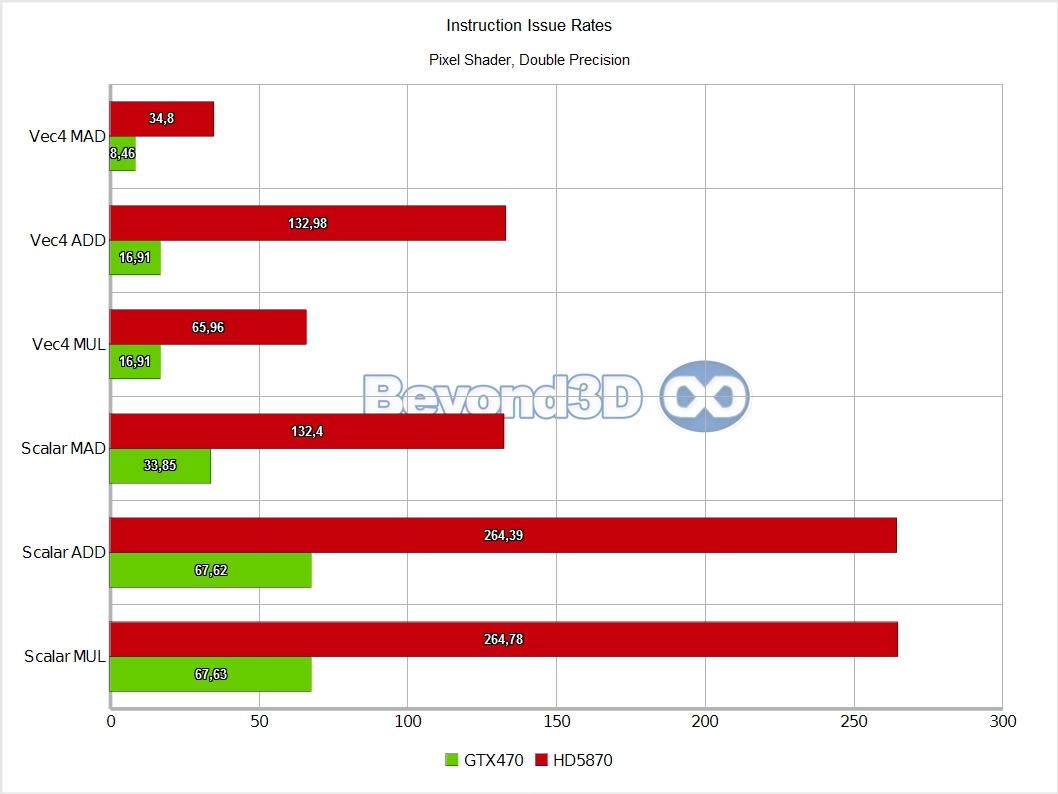
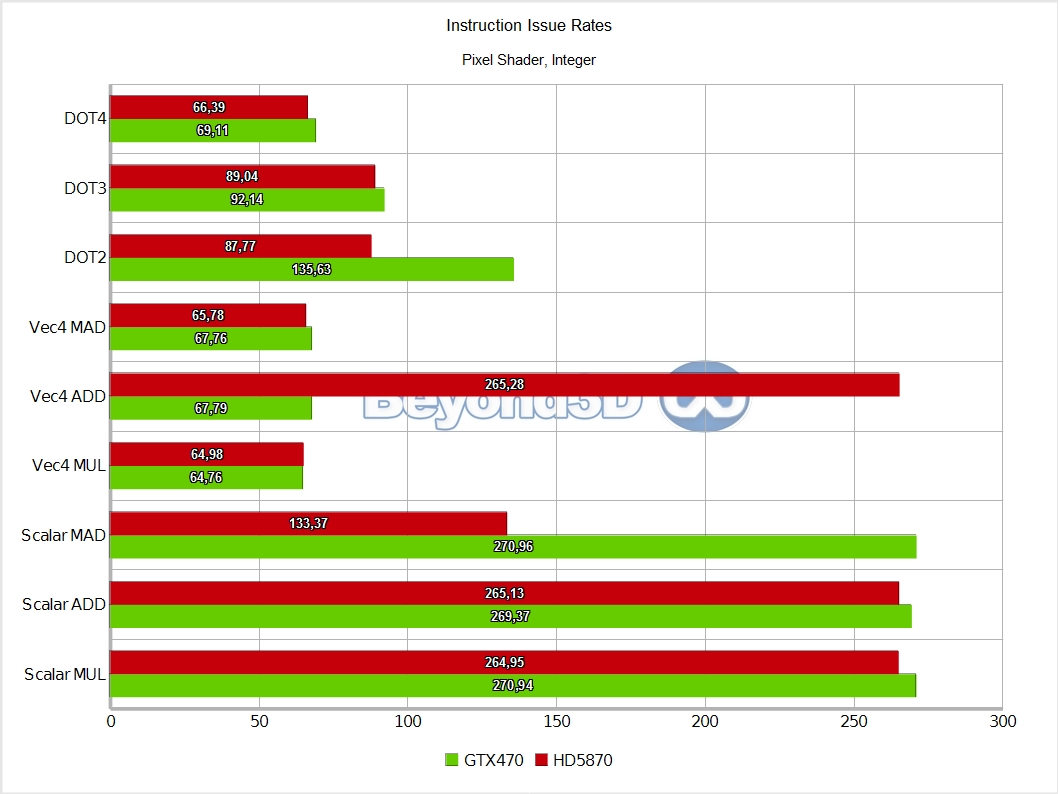
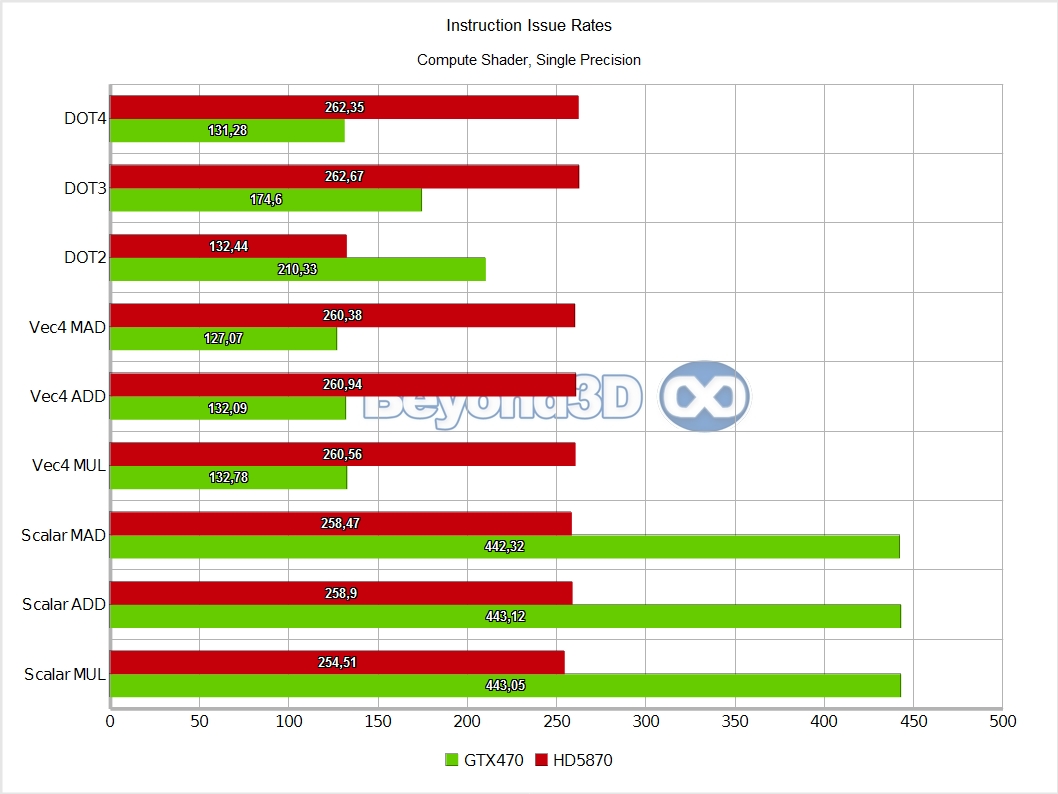
We know, we take the prize for charts per page! There are multiple interesting things to note here, and we'll use a list to do it:
- Vertex thread groups are full rate on Slimer, capped to about half rate on Cypress (probably an artifact of how work scheduling is handled there, with a fixed count for in-flight vertex thread groups being in place).
- Hull thread groups are slow for everyone, achieving ~5% of theoretical rates on Cypress and ~10% on Slimer.
- We think that in the case of Cypress this is a consequence of attempting to keep as much data in shared memory as possible post-HS, which automatically means keeping the data written by a particular HS live in shared memory until a DS consumes it. That can be achieved by limiting the number of HS threads in flight (this is also tied to shared memory requirements, and to probably limited on-chip buffering available pre TS), since these are the only ones that write to shared memory in graphics mode; this is probably fine as long as your HS thread groups aren't very long latency with work to do on each cycle (ours are, we're doing a gazillion math ops...512 to be exact).
- On Fermi we'd have expected it to fare better, but it's possible that the long execution time creates issues with the post-HS redistribution step, and there may also be a thread group cap involved.
- Domain thread groups are half rate on Cypress (this is not surprising, even a simple pass-through shader issued here takes 2 cycles to retire) and as slow as hull ones on Fermi, the latter aspect being a puzzle we haven't quite solved yet (nor have we spent much time on it, to be frank).
- ATI does badly with geometry thread groups, which is both ironic -- remember R600 vs G80? -- and likely an illustration of another scheduling/buffering limitation.
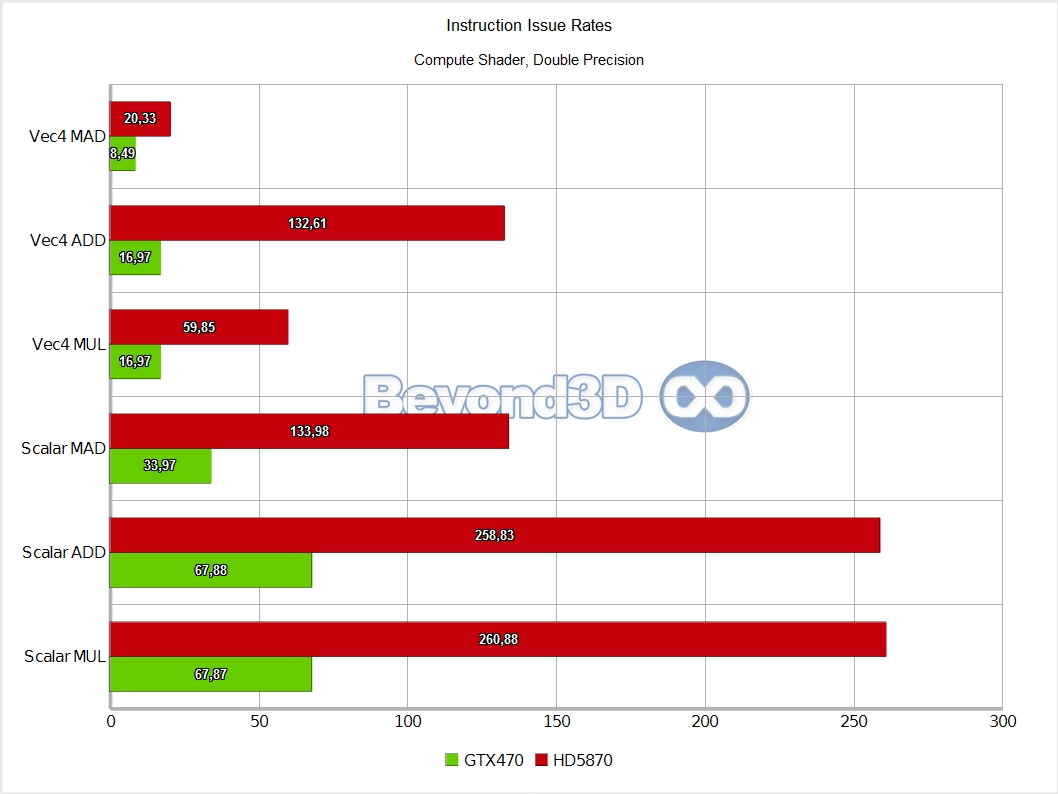
Other than the above, and back to Slimer, we'll have you note that DP math is artificially capped at a quarter of the hardware possible rate (the MAD performance is an artifact of Microsoft's shader compiler generating a MUL and an ADD when the mad intrinsic is used with double operands, and the IHV compilers not fusing that into a FMA, thus making it half of what it can theoretically be).
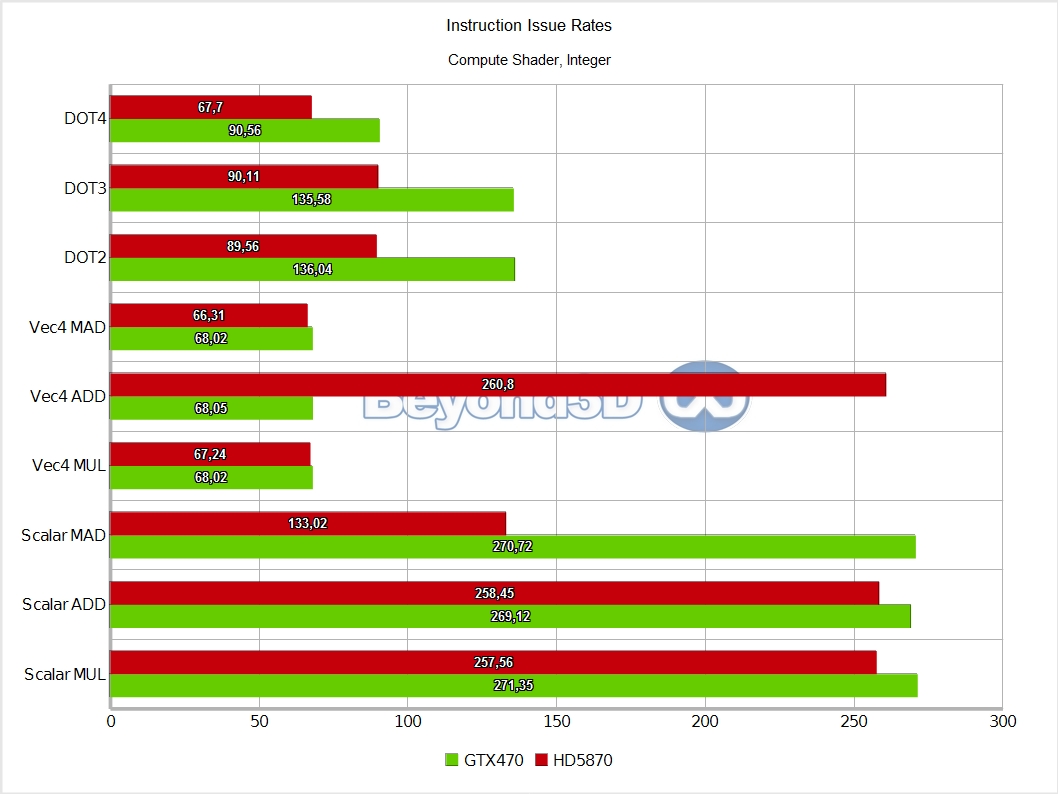
Also, integer performance is exactly half that of SP float, which, as we said, is indicative of the fact that 16 of the ALUs in an SM are actually full blown double precision ALUs, which also handle the 32-bit integer math.
Finally, here's the throughput for some of the more common transcendentals:
Remember that SQRT isn't directly handled by Slimer's SFUs, being implemented via two ops, which explains the half rate. Cypress' low performance with the trig functions is due to the extensive work it does to get the operand in range (we looked at the generated ASM to prove that).