Fermi High-Level View
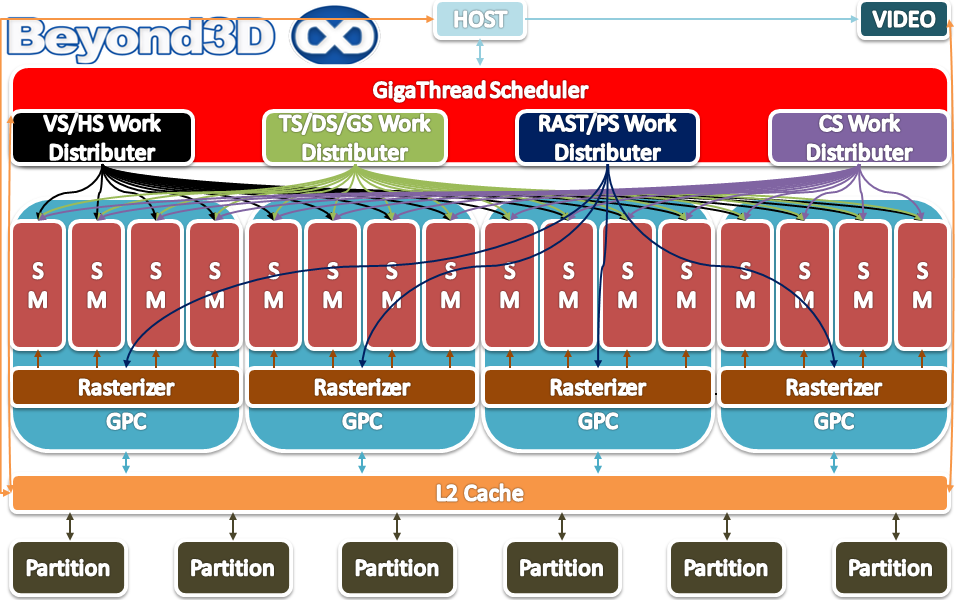
Who would've thunk so many bits can hide within a fat green blob? All joking aside, Fermi is an interesting architectural proposition. It lacks the muscle Cypress proposed many months back, but it implements worthwhile innovations, and tries to compensate via elegance in spots. The coherent L2, for example, is a somewhat significant departure from what has been the norm for GPUs. Going with such a solution has more far-reaching implications – a lot of inter-stage FIFOs get culled, and you end up with a nice fabric for inter-cluster communication. The presence of the L2 is what made the distributed Geometry engine possible, for example.
Versus prior efforts, the overall organisation changes somewhat with Fermi: a new level of aggregation is present, namely the Graphics Processing Cluster (GPC). A GPC is basically a macro-block that subsumes at most 4 stream multiprocessors (SM) with all of their goodies and a rasteriser, having an n-bit interface with the L2 (we'll give the interface substance a bit later on). And no, even if a GPC almost sort of looks like a self contained GPU, calling Fermi the first multi-core GPU or something along those lines is still ridiculous.
Going deeper, the SMs themselves change, going from 8 ALUs per SM to 32 ALUs per SM, for a grand theoretical total of 512 ALUs per full 16 SM enabled GF100 chip. GPU makers in general and NVIDIA in particular would like us to call these cores, but if we start counting SIMD lanes as cores at Beyond3D we might as well give up and hand the keys to Sontin.
Going by instruction counter counts, it's probably somewhat accurate to describe GF100 as a 32-core chip, since each SM can simultaneously schedule and dispatch instructions for two separate thread groups. Alongside the ALUs, each SM gets 4 samplers (no more TPC), 4 special function units (SFU) and 16 load/store units that handle everything involved in accessing memory, including address generation. There are also all sorts of caches we'll deal with in the dedicated section.
The ALUs are fully compliant with IEEE 754-2008, offering FMA for both single and double precision arithmetic. As we've already mentioned, the way geometry work is handled in Fermi is quite intriguing, and the first time we heard about it the name Pomegranate [Eldrige et al, 2000] started dancing happily in the backs of our minds. Which is not to say that it's a 1:1 implementation of what was proposed back then, but it shares a number of significant traits.
And now, cover your eyes gentlemen, it's time to peel the onion!