Previous Limitations of the GPGPU Model
Considering Microsoft's Direct3D 10 system already implements a significantly more flexible programming model, it could be asked why we even need an interface dedicated to GPGPU programming anymore. The first reason against using an existing API is that its implementation is driver-independent. Every new driver version might, somehow, introduce new bugs or change some aspects of the implementation.
But even if we excluded such a factor, the problem remains that neither DirectX nor OpenGL are made with GPGPU as their primary design goals, and this limits their performance for such workloads. Perhaps more importantly, however, arbitrary reads and writes to memory while bypassing the caching system (or flushing it) is still not supported in the Direct3D 10 API.
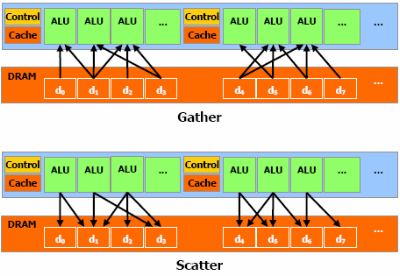
Unsurprisingly, CUDA natively supports both Gather (arbitrary
memory read) and
Scatter (arbitrary memory write) operations. Neither
writes nor reads are cached.
Let us take this opportunity to remind everyone that AMD also introduced their own GPGPU interface last year, CTM ("Close To the Metal"), which is currently hardware accelerated by their R(V)5-series architecture. CTM also supports gather and scatter operations. Excluding the architectural differences between G80 and R580, it might thus appear quite similar to CUDA - it is, however, quite different.
The idea behind CTM is that there is efficiency to be gained by giving an experienced programmer more direct control to the underlying hardware. It is, thus, fundamentally assembly language. CUDA on the other hand aims to simplify GPGPU programming by exposing the system via a standard implementation of the C language. At this point in time, the underlying assembly language output (also known as "NVAsc") is not exposed to the application developer.
Currently, the only public backend CTM is Brook, which abstracts the base interface (Direct3D, OpenGL, CTM and variants therein) and exposes a streaming-like programming model, which fits last-generation hardware pretty much perfectly. The catch, sadly, is that the backend does not expose scatter. Thus, if you need that and want to benefit from CTM, you are pretty much forced to program in assembly language for now.
CTM does have some very nice potential anyway, depending on how it will evolve for the R600 and how the backends evolve. It is not today's subject, however, but trust us to investigate and compare both interfaces in the future. Ease of use, price and performance (per watt?) would certainly be among some of those which we'd like to consider.
Back to the subject at hand, there is a significant facet of CUDA we didn't touch upon yet: efficiency and addressable market. One of NVIDIA's key goals with CUDA was to make it usable for a greater variety of algorithms, while also reducing the amount of CPU interaction necessary in general. Their solution? Thread synchronisation and data sharing. Good, fast and efficient local synchronisation.