Putting it All Together
So, now that we know what CUDA is and what it brings to the table, let's quickly summarize:
- CUDA exposes the NVIDIA G80 architecture through a language extremely close to ANSI C, and extensions to that language to expose some of the GPU-specific functionality. This is in opposition to AMD's CTM, which is an assembly language construct that aims ot be exposed through third party backends. The two are thus not directly comparable at this time.
- The G80 has 16 independent 'multiprocessors', each composed of 8 'processors' (ALUs) that run at twice the clock rate of the scheduler. Each multiprocessor has a 16KiB pool of "shared memory" and each processor has its own register file bank. For obvious reasons, the GeForce 8800 GTS only has 12 multiprocessors activated.
- Threads are grouped in warps (-> branch coherence), which are further grouped in blocks. All the warps composing a block are guaranteed to run on the same multiprocessor, and can thus take advantage of shared memory and local synchronization.
- Shared memory (aka parallel data cache) allows the programmer to manually minimize the number of DRAM accesses necessary by reusing the same data multiple times. If you are familiar with CELL's architecture, you can think of it as a mini-Local Store. If there is more than one block running per multiprocessor, then only a part of shared memory is available to either blocks.
- Local synchronization is extremely efficient as long as there is more than one block running per multiprocessor. The parallel data cache is also the scheme used for communication when synchronization is occuring. This makes it possible to reduce the number of passes (=> CPU interference) and improve efficiency.
It should also be noted that it is possible for CUDA to interface directly with OpenGL and DirectX. Furthermore, the texture units are exposed in CUDA, and unlike normal memory read/writes, they are cached - which might be a good reason to use them for some things, since that cache is idling otherwise. Sadly, only bilinear filtering is exposed at this time, most likely because anisotropic filtering and trilinear would require access to derivatives and mipmap chains in CUDA. We'd still enjoy that functionality, for example to accelerate deferred rendering passes, but it could be argued that it would needlessly complicate the API for those using CUDA for non-rendering workloads, which really is the vast majority of the target audience.
Advantages & Intended Market
On first glance, CUDA and GPGPU in general are primarily aimed at the scientific market. There's a catch there, though; right now, double precision computations (FP64) aren't supported. The good news, however, is that both NVIDIA and AMD have pledged support for this by year's end. Not at full speed, of course, but performance should remain very impressive anyway.
So, what is CUDA currently good for? Plenty of things anyway, it turns out. Here's the marketing graph NVIDIA used at the G80 Editors' Day:
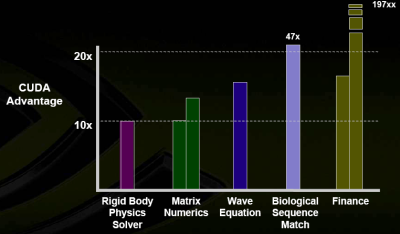
And yes, that *is* actually a 197x speed-up you're seeing there for finance!
The technical reasons behind some of those speed-ups are quite varied. For physics and wave equations, it's quite possible that it's mostly related to the number of GFlops the chip is capable of. For biological sequence match, we honestly aren't too sure ourselves. Matrix Numerics and Finance are two interesting cases to look at, though. Another thing we could look at is the performance of the CUDA FFT and BLAS libraries, but that goes beyond the scope of this article.
Matrix Numerics benefit quite nicely from the parallel data cache, while Finance benefits from the G80's excellent special-function performance. There is an excellent chapter on the latter subject in GPU Gems 2, named "Options Pricing on the GPU". The ratio of special-function operations is very high, and GPUs are both extremely fast and precise for those nowadays. Although it's likely things are being compared with different levels of precision for the CPU and the GPU, the performance difference would remain ludicrously high even with lower CPU precision.
As for Matrix Numerics, NVIDIA's example to showcase the efficiency potential of the parallel data cache and synchronization actually is matrix multiplication. It turns out that by cleverly using those two factors, it is possible to drastically reduce the bandwidth requirements, thus providing significant performance gains. Since the data for each "sub-matrix" is loaded in shared memory by all the threads at the same time, synchronization is necessary before computation can begin.

"sub-matrix" at a time, thus achieving higher bandwidth efficiency than traditional implementations.