New Concepts Behind CUDA, Part 2
Let's first look at how NVIDIA describes CUDA's programming model. Honestly, this single figure pretty much summarises it all:
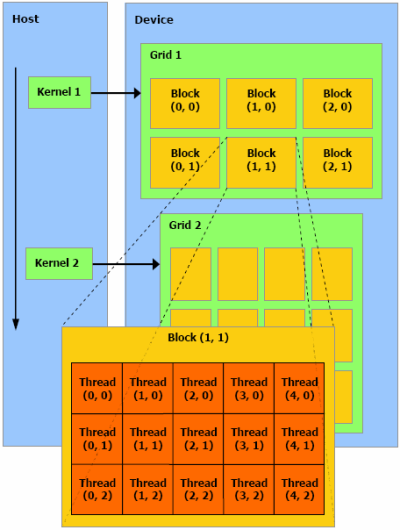
-- David Kirk, NVIDIA
The term 'kernel' comes from the streaming processor world. The CPU invokes a "kernel" to be executed on the GPU, and the kernel is subdivided in grids, blocks and threads. Furthermore, what is not listed on that figure is that threads within a block are further grouped in 'warps'.
While this might seem quite messy on first glance, it really is not. Warps correspond to the group of threads that are scheduled together, which implies that branching ideally should be fully coherent within a single warp for maximal performance. Remember the branch coherence of the G80 is 32 threads.
Warps are then grouped in blocks. The reasoning behind that is that a single block is guaranteed to execute on the same multiprocessor, which allows threads within the same block to communicate and synchronise with each other. The application programmer can specify how many threads should be present in a single block - this affects latency tolerance and the maximum number of available registers, but also the amount of shared memory available. We'll get back to that shortly.
All the blocks are then grouped in a single grid, so that includes all the threads dispatched to the GPU in a single kernel, or 'draw call' as some may wish to think of it. At any time, the GPU program has access to the unique identifier of the block and thread it is currently running. On that note, it should be said that invoking a kernel blocks the CPU; the call is synchronous. If you want to run multiple concurrent kernels (which is actually required for multi-GPU configurations), you need to make use of multithreading on the CPU.
Synchronisation
By now, you're most likely expecting about a gazillion variables and functions related to synchronisation primitives at this point. Well, no, it's all done through a single function call, and it doesn't even take parameters!
__syncthreads() simply allows you to set a synchronisation point, and no code after that point will be executed (barring, perhaps, code related neither to the shared memory nor the device memory) until all threads in the block have finished executing all previous instructions. This makes it possible to efficiently prevent all possible read-after-write hazards for shared memory, as well as for device memory if other blocks aren't interfering with the same memory locations.
In theory, the instruction is nearly free; it doesn't take more time than a single scalar operation of any other time (2 cycles for 32 threads), but there's a small catch. To understand the problem, consider that the ALUs alone likely have 10 stages (which would mean 5 stages from the scheduler's point of view, since it runs at half the frequency). When you are synchronising, what you want to do is make sure that all threads are at same point of execution. What this effectively means is you are flushing the pipeline!
When flushing a pipeline, you are effectively losing at least as many cycles of execution as there are stages in that pipeline. And I'm not even taking memory latency into consideration here, which would complicate things further. For example, if a memory read isn't completed for one warp, all other warps have to keep waiting for it while trying to synchronise! So, needless to say, this is a Bad Thing. Can it be completely fixed? No. Can it be mostly fixed? Yes.
The basic idea is that if you have two blocks running per multiprocessor, then you'll hopefully still have enough threads running to get decent efficiency while the other block is synchronising. You could also run more blocks per multiprocessor (=> less threads per block, all things equal!); for example, if you had 8 blocks running on a single multiprocessor, and synchronisations were rare enough to practically never happen at the same time, you'd still have 87.5% of your threads available to hide memory latency.
So that's how it works for local synchronisation. If you *absolutely* need global synchronisation, remember you could just divide your workload into multiple kernels and let the CPU do the synchronisation. If that doesn't work in your specific case, or it wouldn't be efficient enough, then it is still possible for threads to communicate with each other via device memory, pretty much like you could do it on the CPU. Just make sure you know which blocks are running at a given time for your target GPU architecture, since the number of multiprocessors could vary!
The techniques to prevent read-after-writes hazards in this case are the same that can apply to CPUs, although for the latter, they can sometimes implicitly work through a shared L2 cache. In CUDA's case, there is no memory read/write caching at all, so you need to incur the entire memory latency several times make global synchronisation work. Obviously, in an ideal world, you'd have both very efficient local synchronisation and L2-based global synchronisation, but it looks like we aren't there yet with G80.