Programming and feeding the beast
I know what you're thinking. All these performance-packed pipelines are impressive, but peak numbers are so often misleading. All that horsepower is just for show, unless the thing can be programmed effectively, the data can be parallelized efficiently, and the streams can be loaded quick enough to feed all those ALUs and stored quick enough not to back up the pipeline. And while a VLIW-driven datapath can certainly hike up the peak numbers, filling the execution slots places a burden on a clever, efficient compiler.
Having implemented stream processing not only on their own designs but GPUs as well, Stream Processor personnel were no doubt keenly aware that clean, efficient programming and code portability was critical. The Stream Processing architecture is all about making parallel-processing simpler and more readily accessible, and what could be cleaner than the company's choice to make the system fully software programmable in C?
The Storm-1 includes not one but two MIPS cores, one for handling I/O and running the OS (Linux), and a 2nd (with minimal RTOS) to execute application threads and issue kernel commands to the VLIW-based DPU operating on the stream data. Also keeping things cleaner, while the VLIW-based DPU is the work-horse, it isn't the target of developer's code. SPI's compiler produces the VLIW-code, and it appears by leveraging its own hand-tuned code library.
To ensure the DPU isn't starved for input stream data, nor backed up with output streams waiting to be written, the Stream Processor architecture is based on explicit stream load and stores, rather than demand-based (or prediction-based) fetching through caches. The company claims an aggregate 10.7 GB/s capacity to/from memory via dual 64-bit DDR2 interfaces.
So how well does clean code, lane-based parallelism and high-capacity memory interface manage in the most important goal of keeping as many of the 80 32-bit ALU slots filled? Performing typical video codec transforms and filters, SPI quotes ALU utilization in the 80%+ range for inner-loop processing. Assuming time spent in outer-loops, setup and overhead processing is low, SPI engineers have achieved numbers that would make a lot of designers envious.
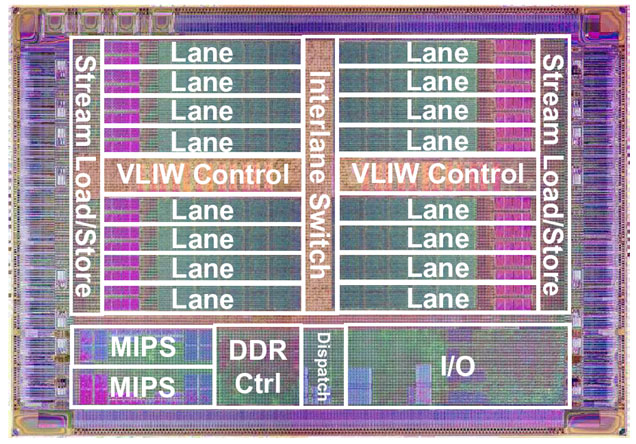
A standard cell implementation in TSMC's 130 nm low-voltage process, Storm-1's frequency is rated at 800 MHz. According to company disclosures, the full Storm-1 SoC contains 34 million transistors, including 896 pins of I/O (not the least of which are 9 SD or 6 HD video ports). The company has a complete Storm-1 evaluation board available now.