Stream Processors, Inc. (SPI) applies general-purpose stream processing to video and image processing
The headliner for ISSCC's media and parallel processing track, Stream Processors, Inc. staged a coming-out party for its new Storm-1, implementing the company's Stream Processing Architecture. No surprise, the first target markets for Storm-1 include video codecs and analytics, and image processing. But stream processing is about general-purpose computing, not just media processing, and the company is expecting Storm-1 to play in wireless infrastructure applications as well.
So what's a stream, anyway? Simply put, it's a finite sequence of data records. In the graphics domain (running on the G80, say), think of tens or hundreds of vertices, each with its own lengthy set of parameters. In the case of Storm-1, think HD video data to encode, image data to analyze, or even communication data for network transport. To a programmer, the stream is generally defined by a base memory pointer, access pattern and length.
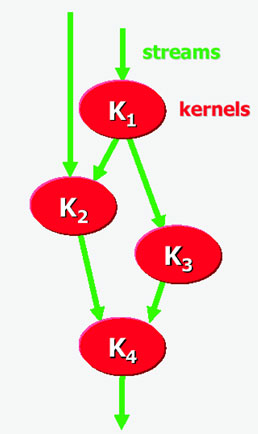
Kernels are where the heavy lifting in the Stream Processing Architecture takes place, repeating one or more operations per set of stream records, over hundreds of possible records in the stream. Kernels encapsulate performance-critical stages of the process flow, such as a filter, transform or motion compensation on a group of frame or field macroblocks.
Kernels - and strings of kernels - execute on streams via four primary commands: Load Kernel, Load Stream, Store Stream and Execute Kernel. Using those basic commands, kernels, running one at a time on the processor, can have output streams linked to input streams of another, creating a more complete and more complex image or video function, say a codec.
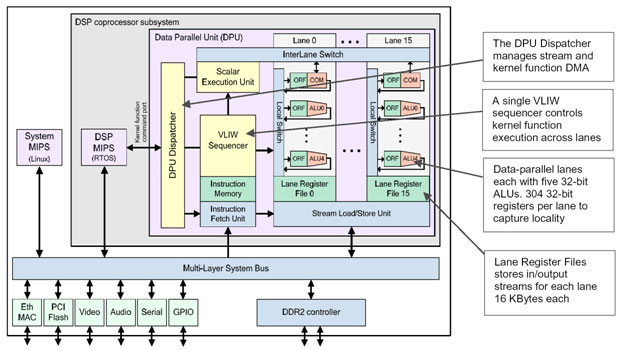
Now let's look under the hood at the engines doing all that kernel-work. Storm-1 implements a large Data Parallel Unit (DPU) of 16 lanes, each with subword SIMD control, driven by a VLIW instruction set with explicit control over the processing pipelines. The 16 lanes operate in parallel, not implementing different kernels, but the same kernel with each lane operating on different records of the stream in parallel.
Each lane contains 5 32-bit ALUs (each capable of a single-cycle multiply-add) supported by a 304-entry 32-bit register file. Add it all up, and running at the nominal 800 MHz frequency, Storm-1 provides an aggregate 512 8-bit GOPS, 256 16-bit GOPS, or 128 16-bit GMACS (Multiply-Accumulate), depending on the width of the sub-word. For example, 5 ALUs × 32-bit/8-bit × 16 lanes × (1 add + 1 mul) × 800 MHz = 512 8-bit GOPs.
Separate 16 KB/lane register files store the input and output streams for staging into or out of memory or funneling back to the DPU for a subsequent kernel stage. The DPU's array of lanes and ALUs is supported by a 20 GB/sec of on-chip interconnect, including a switch to allow output of one lane to feed another without going back off-chip.