Fixed Function Pipeline
The fixed functions of a TnL block are not simple operations, they involve a lot of mathematical operations and even though silicon implementations are very fast every operations (multiplication, addition, divide, etc…) still takes time to execute. Hardware works on the beat of a clock to maintain synchronisation between different areas of the chip. A chips speed depends on the time the slowest block takes, the more functionality you try to place in one block the more time that block will need. Increasing the time needed by one block slows the whole design down since all parts work on the beat of the same clock. Now as said TnL is a fairly complex operation, putting this whole functionality in a single block would result in very long cycle times, which limits the speed of the whole chip. To solve the issue of a single complex block slowing the clock, and thus the whole chip, down a principle known as pipelining was introduced.
Pipelining takes a complex operation and splits it up in small sections where each section is a fairly simple operation that the hardware can execute very quickly. By combining all the small sections in a long “pipeline†the complex operation can be executed.
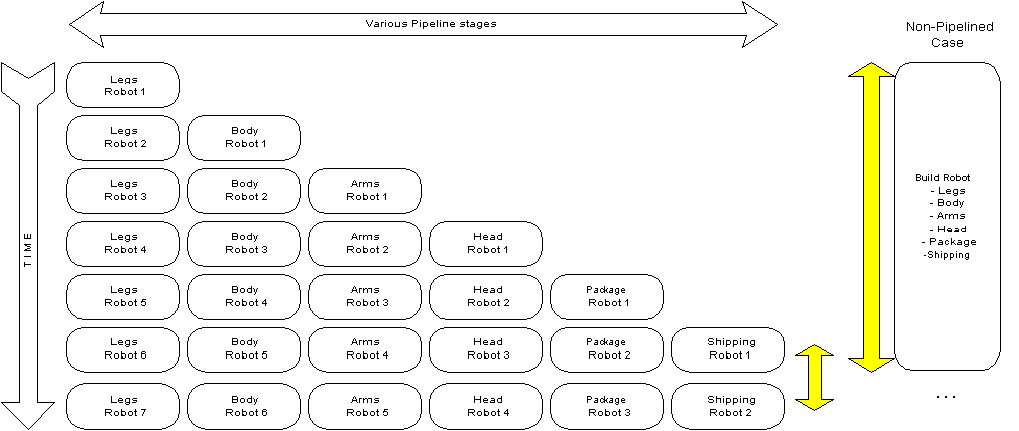
You can imagine this as a production line in a factory, for say a toy robot. In the old days you would have one person making the whole robot, he would take a long time to make one such toy robot. A production line spreads the work load over multiple persons, for example the first stage sets down the legs, next stage connects the body, next stage plugs in the arms, next stage plugs in the head, next stage puts it all in a box, next stage places the box in a truck ready for shipping. The tasks in the production line are all fairly simple and take roughly the same time. The clock cycle time is fairly short given the tasks are simple. The most interesting concept of a pipeline is that all stages can work in parallel. The guy setting down the legs does not have to wait until that first robot is done to set down the next set of legs. As a result a new robot is finished much quicker as the following diagram illustrates, the yellow arrows indicate the speed at which a new robot is completed:
So what’s the problem with this design?
The problem lies in the fixed functionality. The pipeline is designed for one thing and one thing only. As you can see in the diagram at the start of this section I created several blocks: vertex, normal and texture coordinate transform. Now say you don’t need a texture coordinate transform, this will result in valuable silicon sitting idle, wasted, this would be like having a factory pipeline with a group of people available and willing to do work but they are not needed. Obviously this is not very economical.
For lighting I drew a single lighting block capable of executing the lighting maths for one light source, but what if you have multiple lights enabled? The only solution would be to use the same pipeline multiple times for the same vertex. A factory floor example of this would be a toy train with multiple carriages but the production line can only make one carriage at a time, thus resulting in the packaging and storing stages to sit around waiting for enough carriages to be produced to form a complete train. For our hardware this would mean that the transformation side of things can finish a vertex every clock, but the lighting has to process, say, 3 light sources per vertex meaning each vertex has to be passed through the lighting section 3 times, it would take 3 times longer than the transform side. This is known as pipeline stalls or the creation of pipeline bubbles.
The same problem can also happen on the transform side. Say our vertex has 3 texture coordinates, but we only have a single texture transform unit. The only way to execute the task would be to use the texture transform unit 3 times per vertex again effectively stalling the rest of the design.
Vertex blending can also cause a stall where the vertex and normal have to be transformed multiple times (up to 4 times) and the result blended together using the vertex blending weights.
What we notice here is that if the task requires more processing blocks than the hardware pipeline has this will result in pipeline stalls where one processing block sits idle waiting for another block to finish which results in a slowdown and loss of efficiency. It’s important to understand that the inefficiency of one part of the pipeline negatively influences the rest of the pipeline. Lets go back to our robot building example, say that the guy connecting the arms had a little accident earlier that day and works much slower than usually, if he takes twice as long as everybody else then there will be a build-up of robot legs before his station, and all the stations following him will be waiting to get new half-finished robots to work on. The wait periods, known as bubbles, pass through the whole pipeline… everybody suffers from the one “slow†station. If hardware contains a “slow†or “underpowered†station early in the pipeline then the whole hardware will suffer, it’s no good having a fast back-and front-end if the middle part ends up stalling it all.
The biggest problem however remains the fixed functionality - because the pipeline executes a fixed task if a certain task is not needed the hardware goes wasted. With a factory production line its fairly easy to change the pipeline to handle a new product, changing a chip pipeline is impossible… the only task(s) possible are those that the chip pipeline was designed for.
An ideal situation would see more complex operations taking a longer time, while less complex operations take a shorter time to execute with the available resources always used for 100%. Because of the fixed function nature of the design this is not possible, more complex operations can take a longer time but less complex operations can not always take a shorter time to execute. A simplistic example is: a non-used lighting unit can not be used to speed up the transform unit.
The biggest problem with this design is not really efficiency or performance, its flexibility. Fixed function pipelines can be very optimised. Its one single defined task and designing hardware to do this extremely fast is relatively easy. But the cost of this is that only that one single function can be executed and nothing else which can result in pipeline stalls and under-utilisation of the processing capability available depending on the problem presented. Worst if the problem presented is not a sub- or super-set of the pipeline functionality then it can not be executed at all. For example if a different lighting model is required then there is no way to get the pipeline to execute this since the pipeline was designed to do one thing and one thing only.
The low efficiency and low utilisation of the silicon area added to the lack of functional flexibility required for per vertex operations has resulted in the introduction of a different approach: The programmable Vertex Unit.