Analysis: Shader Core Throughput
This will be pretty short, but hopefully sweet. First of all, we'll run some rather simple D3D10 shaders, to see how instruction rate varies in different conditions:
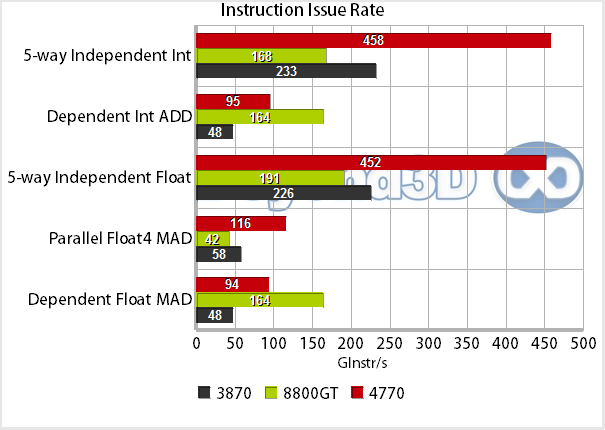
The names should be pretty suggestive for the nature of each shader: for the 5-way independent tests we've set it up so that 5 independent instructions can be executed per cycle, specifically MUL-MAD-MAD-MAD-TRANSCENDENTAL (we've tried SQRT, SIN and COS with similar results) for the FP variant, and 5-way independent ADD for the INT case, which maps to the RV670 and RV740 shader cores quite nicely. Interestingly, neither manages to hit theoretical instruction rates (240 Ginstructions/s for RV670 and 480 Ginstructions/s for RV740), falling a bit short. This can probably be attributed to the fact that the transcendental ALU may not always have the ability to load operands from the GPR pool, as we've already discussed before (shared load ports with the other ALUs).
It's interesting to note that the 8800GT slightly overshoots its theoretical rate, which suggests that it manages to schedule its missing MULs a few times during the loop's execution. The dependent cases are just that, a dependent stream of MADs/ADDs for the FP/INT cases. This is a worst case scenario for the architecture, and not something you're expecting to see a lot of in typical graphics oriented workloads. Finally, the parallel float4 test does a sequence of MADs using FP vec4s as operands. There are no surprises to talk of, we had expected the RV740 to be pretty monstrous when allowed to work its ALUs, and there are no odd quirks to talk about.
Escalating things a bit, we'll be showing you a nice table that centralises the results we've gotten from quite a few shaders written by the guys at Digit-Life/IXBT Labs, and encapsulated in their RightMark3D testing suite. We've gone ahead and included all of them, both the DX9 and the DX10 ones. These cover a few scenarios/typical shader workloads:
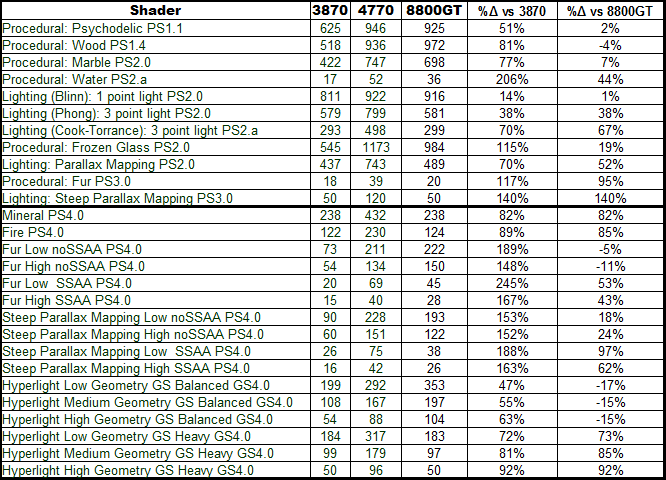
Interestingly enough, we can see super-linear scaling in quite a few shaders (we'd expect the RV740 to double the RV670 based solely on specs). Analysing the cases in which this behaviour is apparent, they typically involve fairly intense texture fetching (the Procedural:Water shader, for example, iterates over a 3D texture to get the procedural noise, and has a very low ALU:TEX ratio), which can lead us to make an educated guess that the scheduler has gotten better at handling latency hiding/texture fetch scheduling, and that it's better at juggling the whole sleep/wake dance it must do with threads that are waiting for a fetch (and those are more numerous in shaders such as those outlined above).
Now that our pixels have been beautified, it's time to write them to the framebuffer, via the ROPs.