Analysis: ROP Throughput
The ROPs proved to be quite interesting beasties, something we hadn't assumed prior to testing. Let's start off neatly by looking at pixel fillrates in different contexts:
Now, this is pretty intriguing: when writing to a 32-bit integer RT, the RV740 seems to be a smidgeon better than the RV670, probably due to a slightly more effective memory controller - nothing to write home about, really! However, enabling blending tackles it in a rather violent fashion, halving its throughput. We'd have penned it on memory bandwidth limitations, but with the same bandwidth the RV670 does better: it takes a hit due to the increased bandwidth requirements, but it's significantly less than 50%. This led us to believe that the RV740's ROPs may be doing blending at half rate.
Looking at the numbers produced when writing to a 64-bit RT adds some weight to this suspicion: RV740's behaviour suggests it can only write 8 pixels per cycle when dealing with a 64-bit RT, and blends are once again half rate. We already knew that the RV670 could only write 8 pixels per cycle under these conditions, and we also know it can do single cycle blending in such cases, which is also supported by the fact that whilst it loses some performance due to bandwidth constraints, it's drop is less than 50%, whereas the RV740 is quite precise in halving its performance. However, when we discussed this with Eric Demers he was adamant that the RV740's ROPs are equal to those found in the RV770, and what we were seeing were bandwidth constraints. That being the case, it's interesting to note that under these particular circumstances, RV670 does better with the same available bandwidth, which would indicate that this is a case in which a wider lower-clocked bus is preferable to a narrower higher clocked one, in spite of theoretical throughput being equal.
Having gone through the first bog, it's time to move on to the stingy subject of AA performance, and see what the impact of the ROP overhaul is on this front:
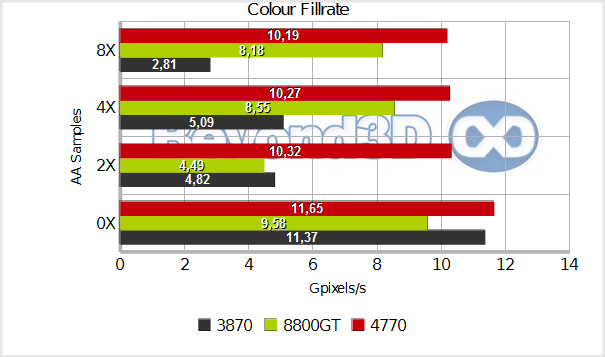
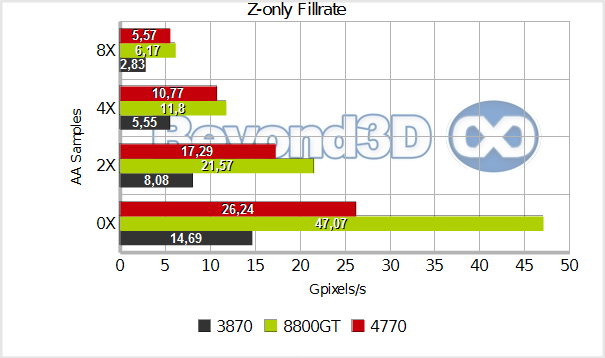
We should discuss the Z-only rates a bit, since they're so far off from their theoretical values (note, these are for a 24-bit Z-buffer). This is a consequence of bandwidth constraints, primarily: all of these GPUs can, in theory, write quite a few zixels to the framebuffer – the 8800 GT is rather scary actually, with 76.8 Gzixels/s, and the RV740 is no slouch either, with 48 Gzixels/s – however, their memory interface, and the fact that maximum Z compression for all tiles will almost always never happen makes it practically impossible for these values to be reached. The best performer with regards to no-AA Z-only rates is the 8800 GT which hits almost 60% of its potential, also by virtue of its higher 57.6GB/s bandwidth.
This means that on average the achieved compression rate was 2.36:1 ((3bytes per z-value*achieved Z-fill)/bandwidth) – a far cry from the pretty high rates typically quoted. The RV670 does quite badly here, not even hitting the rate its bandwidth would allow if no compression were in place(17.36 zixels in theory), which may have something to do with the fact that we down-clocked its memory, or with the way our test is setup. The RV740 improves on that, but is still moderately bad (1.53:1 Z-compression rate -- hey, this means there were some tweaks in this area too, versus the RV670). We'll have to investigate this further, but it makes for an interesting data-point certainly, and for good coffee chats....if your coffee chats involve GPUs, that is.
Enabling AA changes the playing field a bit. The RV670 behaves a bit oddly, given the fact that it can test 2 sample positions per cycle (as evidenced by the 4xAA numbers), and yet the 2x AA throughput would lead one to believe that it's a 1 test per cycle affair. However, this is acknowledged by ATI (see Scott Hartog's presentation from the RV770's launch for an illustration), and we believe that it's a limitation of the fast-path between the ROPs and the Shader Core. For 2x AA the resolve math is quite trivial (a vec3 MAD, more or less), so it's not the resolve step that's the limitation, but (we guess) the rate at which partially compressed tiles can be decompressed in the ROP, passed to the SIMDs, and then passed back.
The other modes behave as expected. We have no idea why the 8800 GT bombs at 2x AA, but we'll pen it on the fact that nowadays no-one cares about that mode any more, so it's the least likely candidate to receive driver optimisations. RV740 is quite puzzling, in that the colour-fill cost of AA is very very low on this GPU – that's expected for 2X and 4X modes, since it can test up to 4 sample positions per cycle – but the very low drop attached with the extra loop needed to test 8 positions is quite surprising.
Z-rates bring no new surprises, beyond the initially discussed aspects...as long as you're not playing with high-precision floating-point depth formats! Because if you are, this may be of interest:
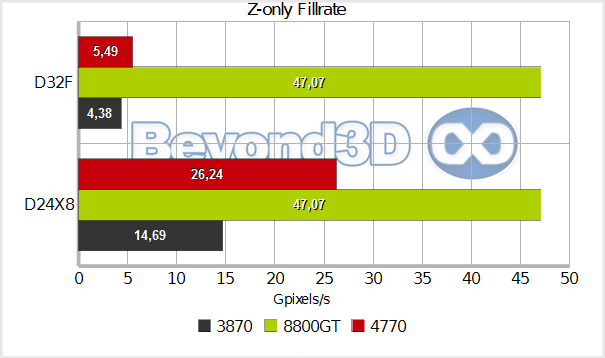
Whoa! That's quite a high price to pay indeed. What could cause such a drop? We've done some digging, and arrived at the conclusion that both the RV670 and the RV740 disable Z-compression when writing to FP depth formats (we've gone ahead and manually disabled it and integer Z-only rates fell to parity with what you can see in the chart above). Discussing things with ATI, they shared that a bug was indeed present in earlier drivers, but it should have been fixed long ago, insisting that the limitation resided in our application. Look for an elaboration on this topic soon.
Now, to close things with the ROPs, we took a rather old demo (namely ATI's Rachel demo, from a time when the Radeon 8500 was supposed to be really great, which may seem like never, but trust us, the demo exists), and tested various AA modes. We chose this path in order to do something a tad less synthetic, but still far from bringing in the sea of confounding factors that come with modern game engines. First, the base modes:
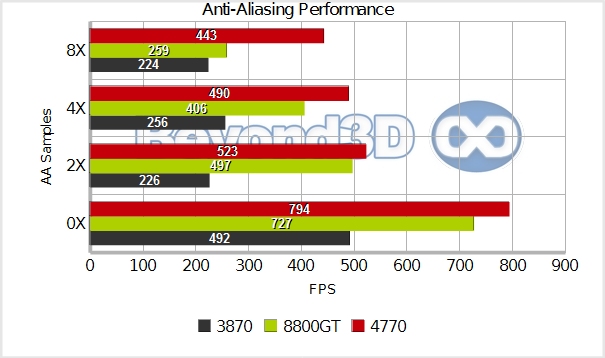
The 8800 GT is quite fast without AA, but loses out at higher sample densities – seems like the new and improved ROPs are quite good when it comes to AA throughput. RV670 is the poor chap that brought a knife to a gun-fight in this particular situation -- not unexpected, though. Finally, let's perform that wonky experiment we suggested upstream, and attempt to isolate the cost of moving resolve to the shader core. Take a look at this chart, that outlines the cost of enabling the narrow tent resolve filter on top of 2x AA:
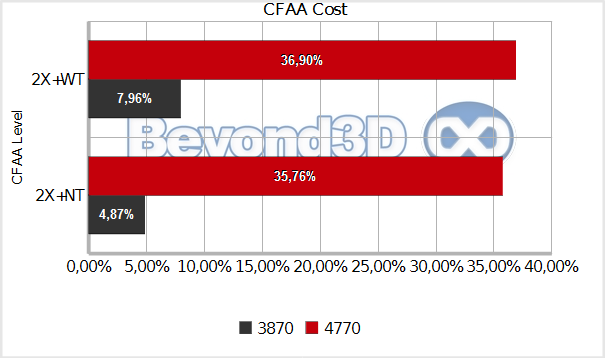
We're looking at 2x AA and the narrow-tent in order to be sure that the resolve itself doesn't become a limiting factor, and that the ALUs chew through it easily. For RV670, the cost of enabling the narrow-tent filter is mainly tied to doing 1 extra vec3 MAD in the resolve shader (or the equivalent), instead of just one, since it's already doing resolve on the ALUs even for the base 2X mode. However, RV670 has to forego the rapid ROP-based resolve, and also add the extra latency of transferring tiles to the shader core...so if we do a simple difference between the RV740 cost and the RV670 cost, we should be left with the cost of shader-based resolve, which ends up being a pretty hefty 31%! Whilst there's certainly some juggling room (perhaps a few % points less, perhaps a few % points more), the fact remains that this is quite expensive, and should give a bit of extra perspective into the AA woes of the R6xx cards.
Summing up the ROPs, they're quite good in practice and in modes that the majority probably cares about (integer pixels with AA). ATI seems to have gimped write rates to FP64 framebuffers and blending, but given the flimsy available bandwidth we can't fault them. The D32F situation was a surprise, and worth digging into further, which is what we're doing at the moment.
You can all sigh in relief now, because it's now time to wrap things up, with a quick test of the tessellator, a glimpse at PCI Express throughput, and our conclusions.